We recommend working with this notebook on Google Colab
![]()
Assessing Accuracy of the Tide Predictions of the Ocean State Ocean Model#
Author of this document: Grace Kowalski ![]()
Edited by: Timothy Divoll ![]()
The purpose of this notebook is to use National Oceanic and Atmospheric Administration (NOAA) tide data to better understand the behavior of tides in the Narragansett Bay, as well as using Ocean State Ocean Model (OSOM) tide data to see how accurately the model is predicting the observed water level. This notebook is a great practice in organizing and visualzing data. There are various colorful plots being made to best visualize the findings.
The observed water level data was collected from 9 tide gauges within the Narragansett Bay boundary from the National Oceanic and Atmospheric Administration’s Center for Operational Oceanographic Products and Services (NOAA CO-OPS) over the years 2004 to current. The NOAA CO-OPS gauges also had water level predicted by NOAA that we collected for the same locations and time period. The OSOM water level data was collected for the same 9 locations using the closest latitude and longitude points as the NOAA gauges, only for the year of 2017. All of this was collected and analyzed in meters.
Firstly, we need to install and import the necessary packages to run the code.
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
import numpy as np
import netCDF4 as nc
from netCDF4 import num2date, date2num, date2index
from pathlib import Path
Next, we should read in all of the data we want to use. The data downloaded directly from the NOAA webpage is in comma-separated value form, so we write a function to specifically read in .csv files. From reading those files, the variables for time, predicted waterlevel, and verified waterlevel will be put into lists. These lists will store all of that data for plotting and further data manipulation.
Manual data download#
The following is an example of how to work with data downloaded from the NOAA webpage (https://tidesandcurrents.noaa.gov/stations.html?type=Water+Levels)
#Define a function to read csv files and make a list of variables to be used
def readcsv(document, skiprows=6):
#Open the file and read it
df = pd.read_csv(document, sep=",", na_values=["-"], skiprows=skiprows)
#Make three separate lists for the date, hour, and water level variables
date=df['Date'].tolist()
hour=df['Time (GMT)'].tolist()
level=df['Verified (m)'].tolist()
predicted=df['Predicted (m)']
#Merge the date and hour lists
time=[]
for i in range(len(date)):
time.append(date[i]+" "+ hour[i])
return time, level, predicted
Next, we can call this function to read in all the files. We have 9 files of hourly buoy data for each of the 9 stations.
Set up paths to load data and save results#
Execute the commands below directly in this notebook to connect to your Google Drive (via Colab) or set a path locally.
NOTE: If you are working in Google Colab, the next block will dowenload data folders from the remote repo, otherwise, the folders will be in the current local directory
try:
!npx degit ridatadiscoverycenter/riddc-jbook/notebooks_data#main notebooks_data
!npx degit ridatadiscoverycenter/riddc-jbook/test_data#main test_data
!mkdir "./plots"
!mkdir "./plots/tide_plots"
raw_data_dir = "./notebooks_data/"
test_data_dir = "./test_data/"
plots_dir = "./plots/"
except ModuleNotFoundError:
import os
raw_data_path = "../../notebooks_data/"
test_data_path = "../../test_data/"
plots_path = "../../plots/"
parent_dir = "../"
raw_data_dir = os.path.join(parent_dir, raw_data_path)
test_data_dir = os.path.join(parent_dir, test_data_path)
plots_dir = os.path.join(parent_dir, plots_path)
#Read in all the files
#Make sure to title all the lists so that they are different from each other
time_8447386, water_8447386, predicted_8447386 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8447386_met.csv')
time_8447930, water_8447930, predicted_8447930 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8447930_met.csv')
time_8449130, water_8449130, predicted_8449130 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8449130_met.csv')
time_8452660, water_8452660, predicted_8452660 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8452660_met.csv')
time_8452944, water_8452944, predicted_8452944 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8452944_met.csv')
time_8454000, water_8454000, predicted_8454000 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8454000_met.csv')
time_8454049, water_8454049, predicted_8454049 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8454049_met.csv')
time_8461490, water_8461490, predicted_8461490 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8461490_met.csv')
time_8510560, water_8510560, predicted_8510560 = readcsv(f'{raw_data_dir}tides/met/CO-OPS_8510560_met.csv')
View a slice of the data from manual download and cleaning process.
time_8510560[0:5], water_8510560[0:5], predicted_8510560[0:5]
(['1/1/2004 0:00',
'1/1/2004 1:00',
'1/1/2004 2:00',
'1/1/2004 3:00',
'1/1/2004 4:00'],
[0.23, 0.145, 0.1, 0.102, 0.149],
0 0.308
1 0.243
2 0.165
3 0.119
4 0.140
Name: Predicted (m), dtype: float64)
Now compare with the data generated in the noaa_coops_download notebook. Note: use the optional skiprows=None argument when using data generated with this method.
time_directdl_8510560, water_directdl_8510560, predicted_directdl_8510560 = readcsv(f'{test_data_dir}montauk_tide_data.csv', skiprows=None)
time_directdl_8510560[0:5], water_directdl_8510560[0:5], predicted_directdl_8510560[0:5]
(['01/01/2004 00:00',
'01/01/2004 01:00',
'01/01/2004 02:00',
'01/01/2004 03:00',
'01/01/2004 04:00'],
[0.23, 0.145, 0.1, 0.102, 0.149],
0 0.308
1 0.243
2 0.165
3 0.119
4 0.140
Name: Predicted (m), dtype: float64)
The first plot we will make are weekly plots for each station. This can be done by using the lists we formed above and separating out the dates we want by using the year and month. The plot will be 4 subplots for each week of the month of interest.
#Define a function to plot each week in a month as a subplot
#The "time" variable is the list of time created above for the station of interest (choose any station)
#The "water_level" variable is the list of NOAA verified water level for that same station
#The "year" variable is the year of interest
#The "month" variable is the month of interest
#The 4 "title" variables are the title of each subplot
#The "file" variable is the pathway name to save the figure
def weeklyplots(time, water_level, year, month, title1, title2, title3, title4, file):
#Create a list where it ends in only the year you want
yr=[]
yr_level=[]
for k in range(len(time)):
if year in time[k]:
yr.append(time[k])
yr_level.append(water_level[k])
#Creat a list where the first part of the string is the month you want to only get that month
mmyr=[]
mmyr_water_str=[]
for i in range(len(yr)):
if yr[i].startswith(month):
mmyr.append(yr[i])
mmyr_water_str.append(yr_level[i])
week1_str=[]
week1_water_str=[]
week2_str=[]
week2_water_str=[]
week3_str=[]
week3_water_str=[]
week4_str=[]
week4_water_str=[]
for j in range(len(mmyr)):
#Say that if the date contains these days in the middle, that is week one. So days 1 through 7
if "/1/" in mmyr[j] or "/2/" in mmyr[j] or "/3/" in mmyr[j] or "/4/" in mmyr[j] or "/5/" in mmyr[j] or "/6/" in mmyr[j] or "/7/" in mmyr[j]:
week1_str.append(mmyr[j])
week1_water_str.append(mmyr_water_str[j])
#Days 8 through 14 are week 2
elif "/8/" in mmyr[j] or "/9/" in mmyr[j] or "/10/" in mmyr[j] or "/11/" in mmyr[j] or "/12/" in mmyr[j] or "/13/" in mmyr[j] or "/14/" in mmyr[j]:
week2_str.append(mmyr[j])
week2_water_str.append(mmyr_water_str[j])
#Days 15 through 21 are week 3
elif "/15/" in mmyr[j] or "/16/" in mmyr[j] or "/17/" in mmyr[j] or "/18/" in mmyr[j] or "/19/" in mmyr[j] or "/20/" in mmyr[j] or "/21/" in mmyr[j]:
week3_str.append(mmyr[j])
week3_water_str.append(mmyr_water_str[j])
#Days 22 through 31 are week 4
elif "/22/" in mmyr[j] or "/23/" in mmyr[j] or "/24/" in mmyr[j] or "/25/" in mmyr[j] or "/26/" in mmyr[j] or "/27/" in mmyr[j] or "/28/" in mmyr[j] or "/29/" in mmyr[j] or "/30/" in mmyr[j] or "/31/" in mmyr[j]:
week4_str.append(mmyr[j])
week4_water_str.append(mmyr_water_str[j])
#Make the list of string dates into datetime
week1=[]
week2=[]
week3=[]
week4=[]
for l in range(len(week1_str)):
week1.append(datetime.strptime(week1_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week2_str)):
week2.append(datetime.strptime(week2_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week3_str)):
week3.append(datetime.strptime(week3_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week4_str)):
week4.append(datetime.strptime(week4_str[l], '%m/%d/%Y %H:%M'))
#Make the list of weekly water level strings into floats
week1_water=[]
week2_water=[]
week3_water=[]
week4_water=[]
for i in range(len(week1_water_str)):
week1_water.append(float(week1_water_str[i]))
for i in range(len(week2_water_str)):
week2_water.append(float(week2_water_str[i]))
for i in range(len(week3_water_str)):
week3_water.append(float(week3_water_str[i]))
for i in range(len(week4_water_str)):
week4_water.append(float(week4_water_str[i]))
#Making subplots. I want 4 vertical plots and for them to share a y-axis
fig, axs=plt.subplots(4, figsize=(35,35), sharey = True)
x1 = week1
y1=week1_water
x2 = week2
y2=week2_water
x3 = week3
y3=week3_water
x4 = week4
y4=week4_water
axs[0].plot(x1, y1)
axs[1].plot(x2, y2)
axs[2].plot(x3, y3)
axs[3].plot(x4, y4)
#Making title of each plot
axs[0].set_title(title1, fontsize=20)
axs[1].set_title(title2, fontsize=20)
axs[2].set_title(title3, fontsize=20)
axs[3].set_title(title4, fontsize=20)
#Setting font of the axes
axs[0].xaxis.set_tick_params(labelsize=18)
axs[1].xaxis.set_tick_params(labelsize=18)
axs[2].xaxis.set_tick_params(labelsize=18)
axs[3].xaxis.set_tick_params(labelsize=18)
axs[0].yaxis.set_tick_params(labelsize=18)
axs[1].yaxis.set_tick_params(labelsize=18)
axs[2].yaxis.set_tick_params(labelsize=18)
axs[3].yaxis.set_tick_params(labelsize=18)
#plt.show
plt.savefig(file)
#Call the function to make the plots
#Making weekly plots for every month in 2006 at the 8447386 station
weeklyplots(time_8447386, water_8447386, "/2006", "1/", "January 2006 Week 1 8447386", "January 2006 Week 2 8447386", "January 2006 Week 3 8447386", "January 2006 Week 4 8447386", f'{plots_dir}tide_plots/January_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "2/", "February 2006 Week 1 8447386", "February 2006 Week 2 8447386", "February 2006 Week 3 8447386", "February 2006 Week 4 8447386", f'{plots_dir}tide_plots/February_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "3/", "March 2006 Week 1 8447386", "March 2006 Week 2 8447386", "March 2006 Week 3 8447386", "March 2006 Week 4 8447386", f'{plots_dir}tide_plots/March_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "4/", "April 2006 Week 1 8447386", "April 2006 Week 2 8447386", "April 2006 Week 3 8447386", "April 2006 Week 4 8447386", f'{plots_dir}tide_plots/April_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "5/", "May 2006 Week 1 8447386", "May 2006 Week 2 8447386", "May 2006 Week 3 8447386", "May 2006 Week 4 8447386", f'{plots_dir}tide_plots/May_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "6/", "June 2006 Week 1 8447386", "June 2006 Week 2 8447386", "June 2006 Week 3 8447386", "June 2006 Week 4 8447386", f'{plots_dir}tide_plots/June_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "7/", "July 2006 Week 1 8447386", "July 2006 Week 2 8447386", "July 2006 Week 3 8447386", "July 2006 Week 4 8447386", f'{plots_dir}tide_plots/July_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "8/", "August 2006 Week 1 8447386", "August 2006 Week 2 8447386", "August 2006 Week 3 8447386", "August 2006 Week 4 8447386", f'{plots_dir}tide_plots/August_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "9/", "September 2006 Week 1 8447386", "September 2006 Week 2 8447386", "September 2006 Week 3 8447386", "September 2006 Week 4 8447386", f'{plots_dir}tide_plots/September_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "10/", "October 2006 Week 1 8447386", "October 2006 Week 2 8447386", "October 2006 Week 3 8447386", "October 2006 Week 4 8447386", f'{plots_dir}tide_plots/October_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "11/", "November 2006 Week 1 8447386", "November 2006 Week 2 8447386", "November 2006 Week 3 8447386", "November 2006 Week 4 8447386", f'{plots_dir}tide_plots/November_2006_Weekly_8447386.png')
weeklyplots(time_8447386, water_8447386, "/2006", "12/", "December 2006 Week 1 8447386", "December 2006 Week 2 8447386", "December 2006 Week 3 8447386", "December 2006 Week 4 8447386", f'{plots_dir}tide_plots/December_2006_Weekly_8447386.png')
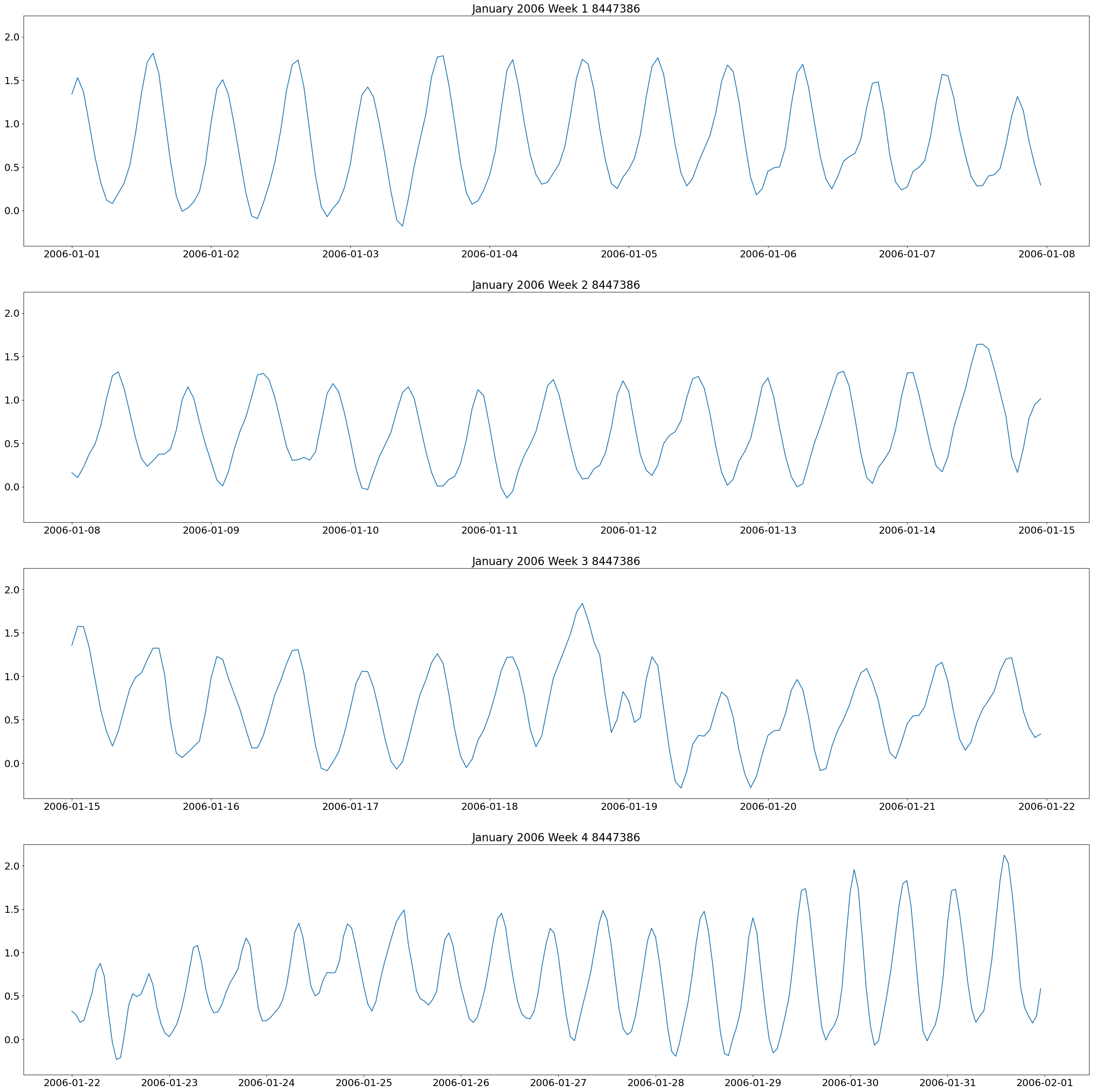
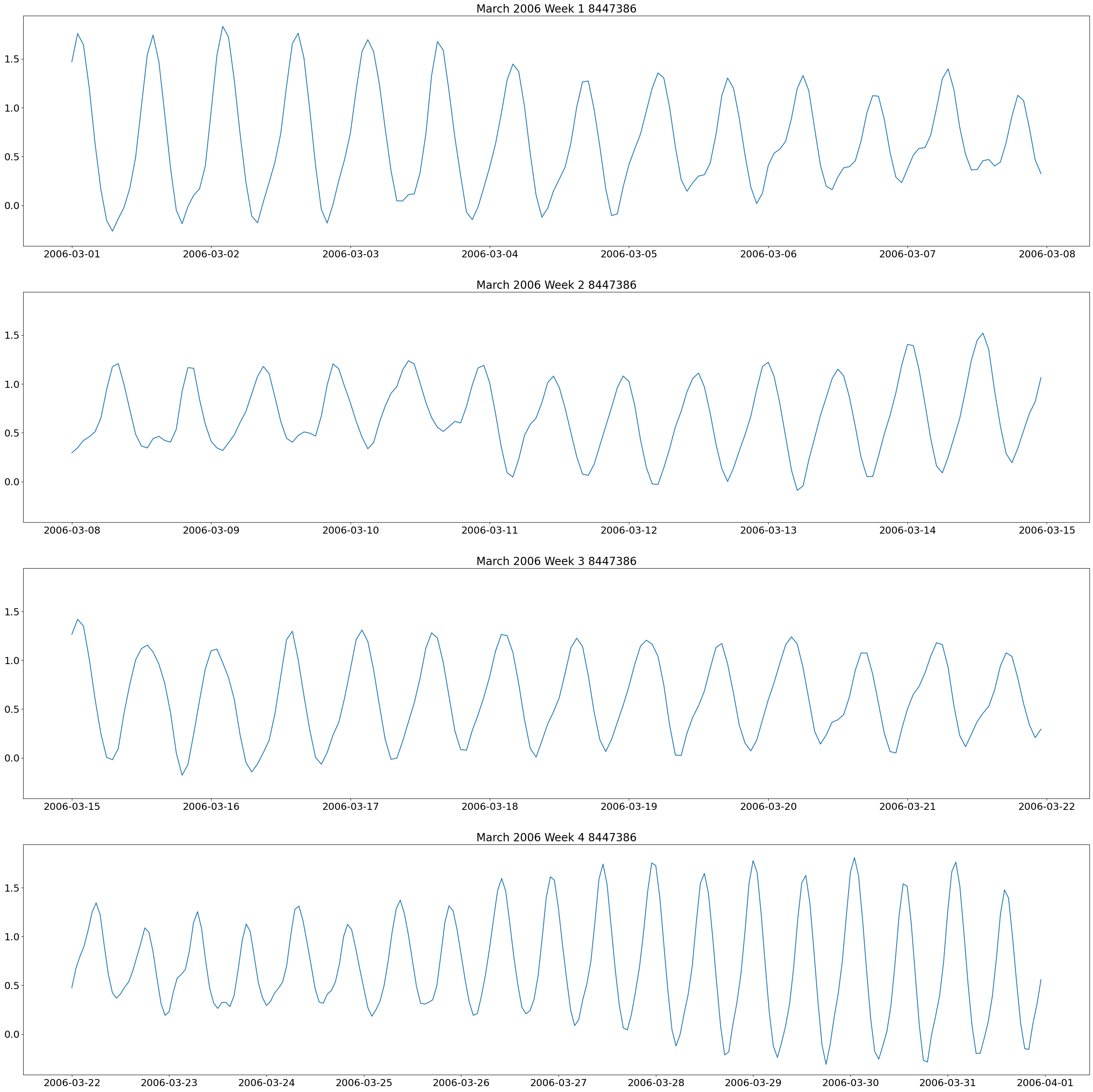
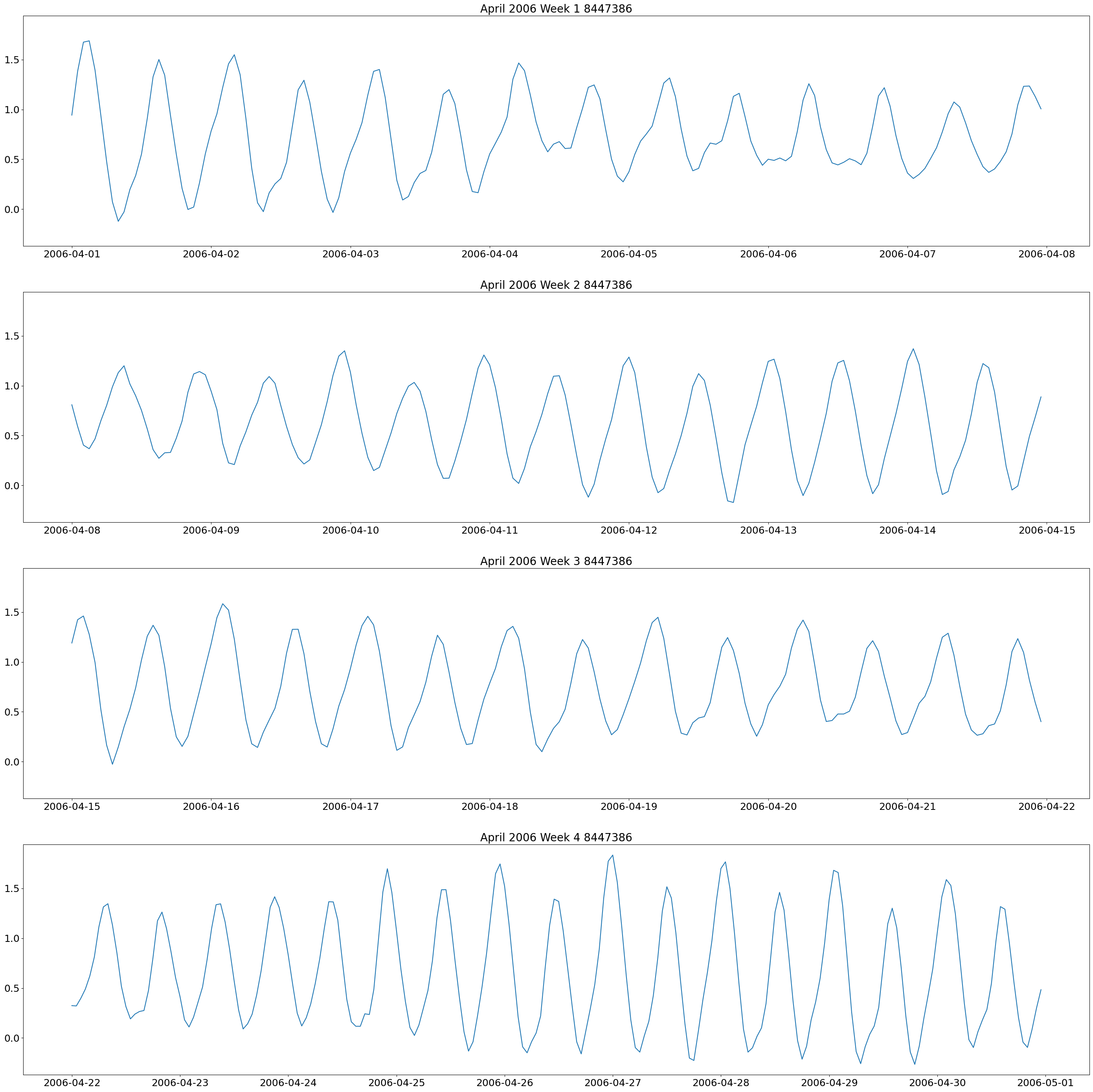
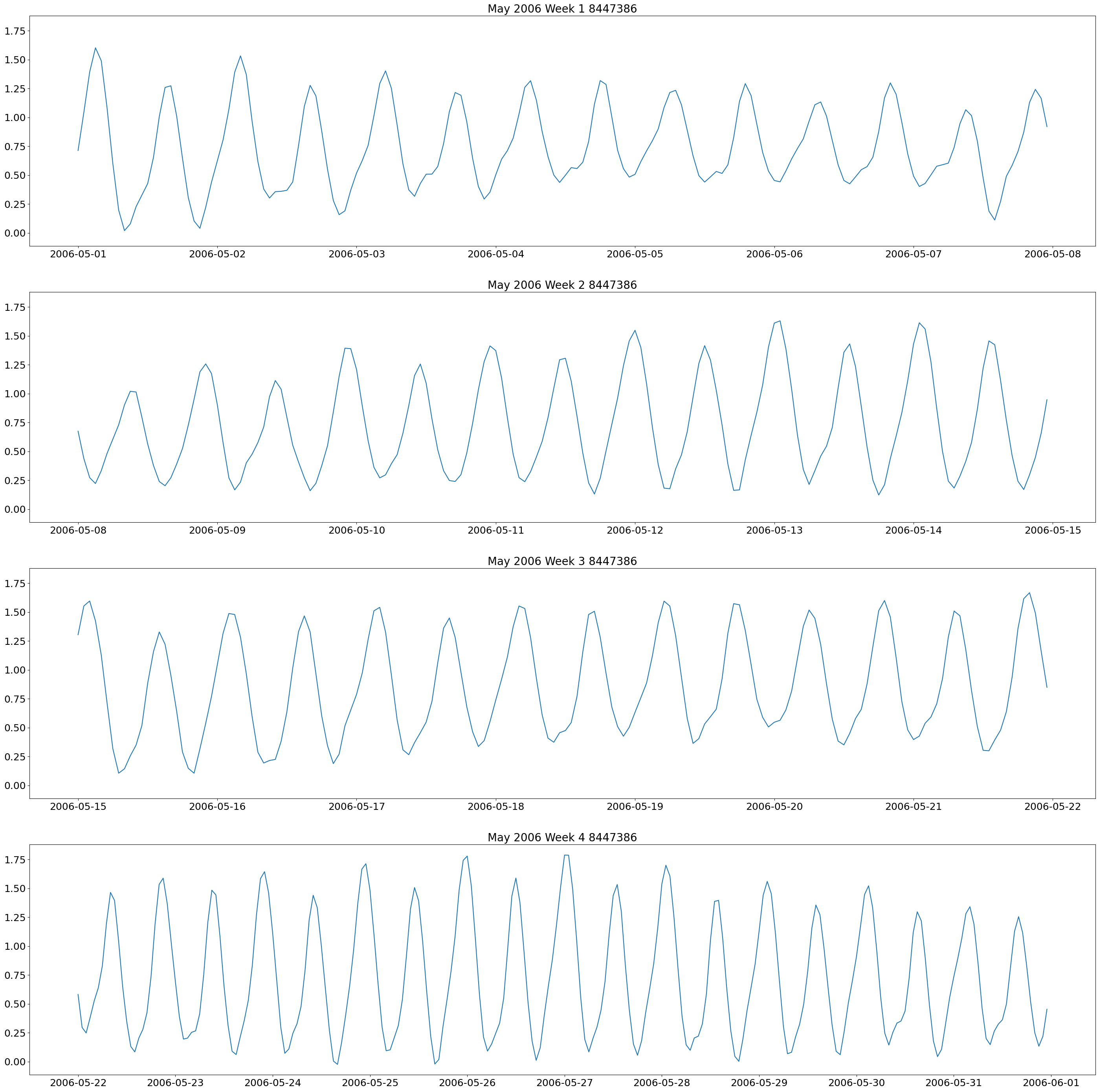
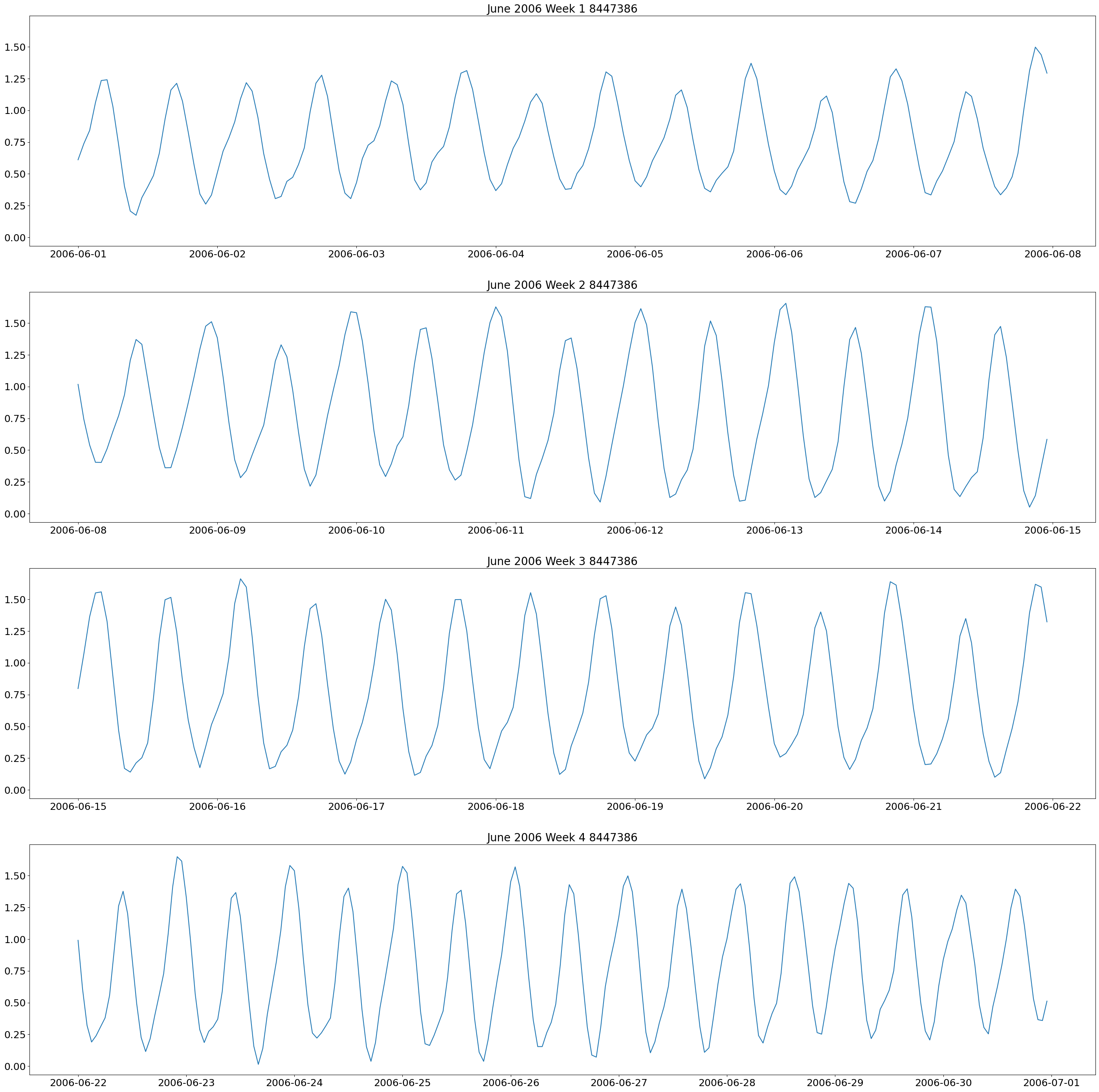
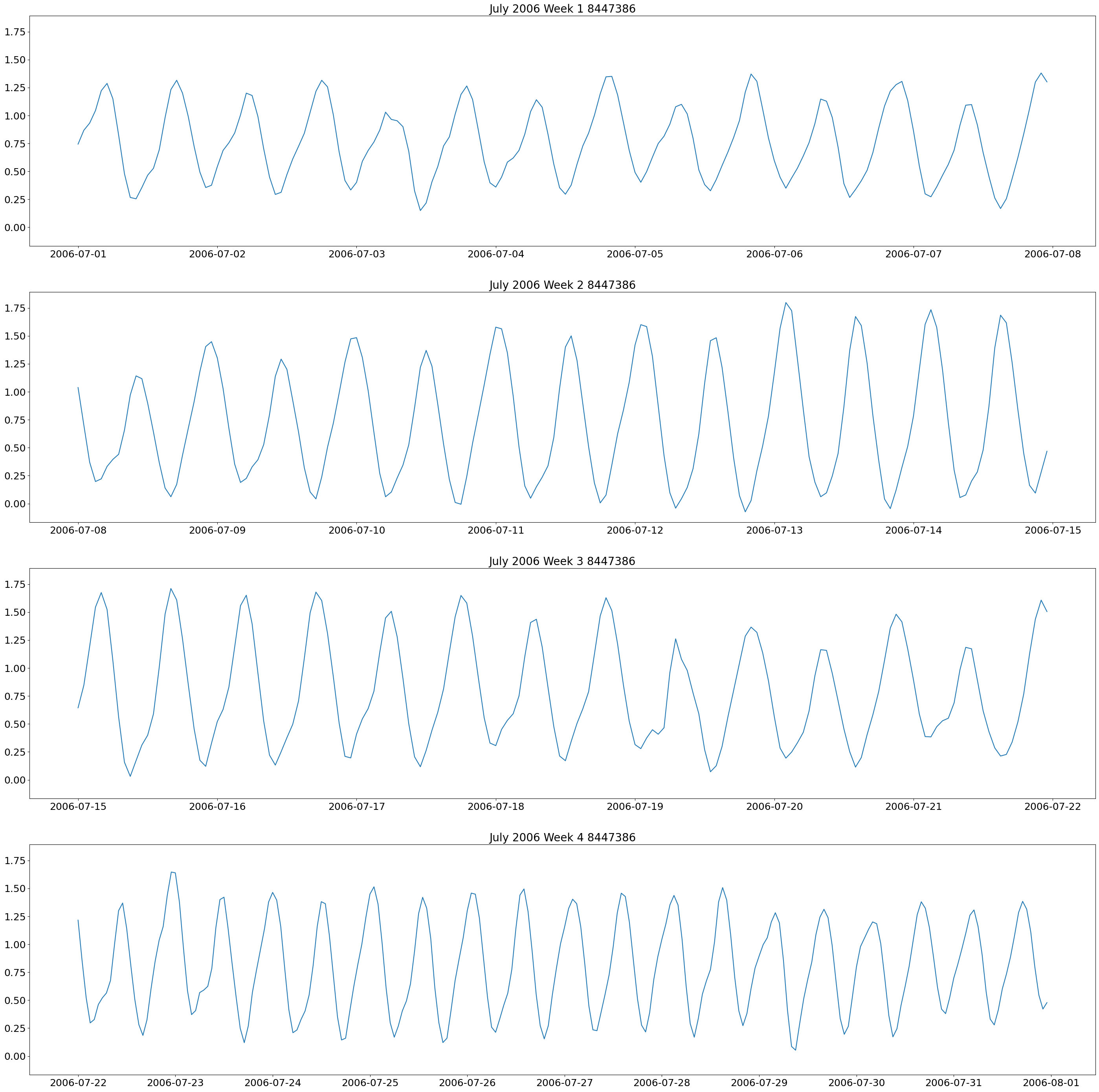
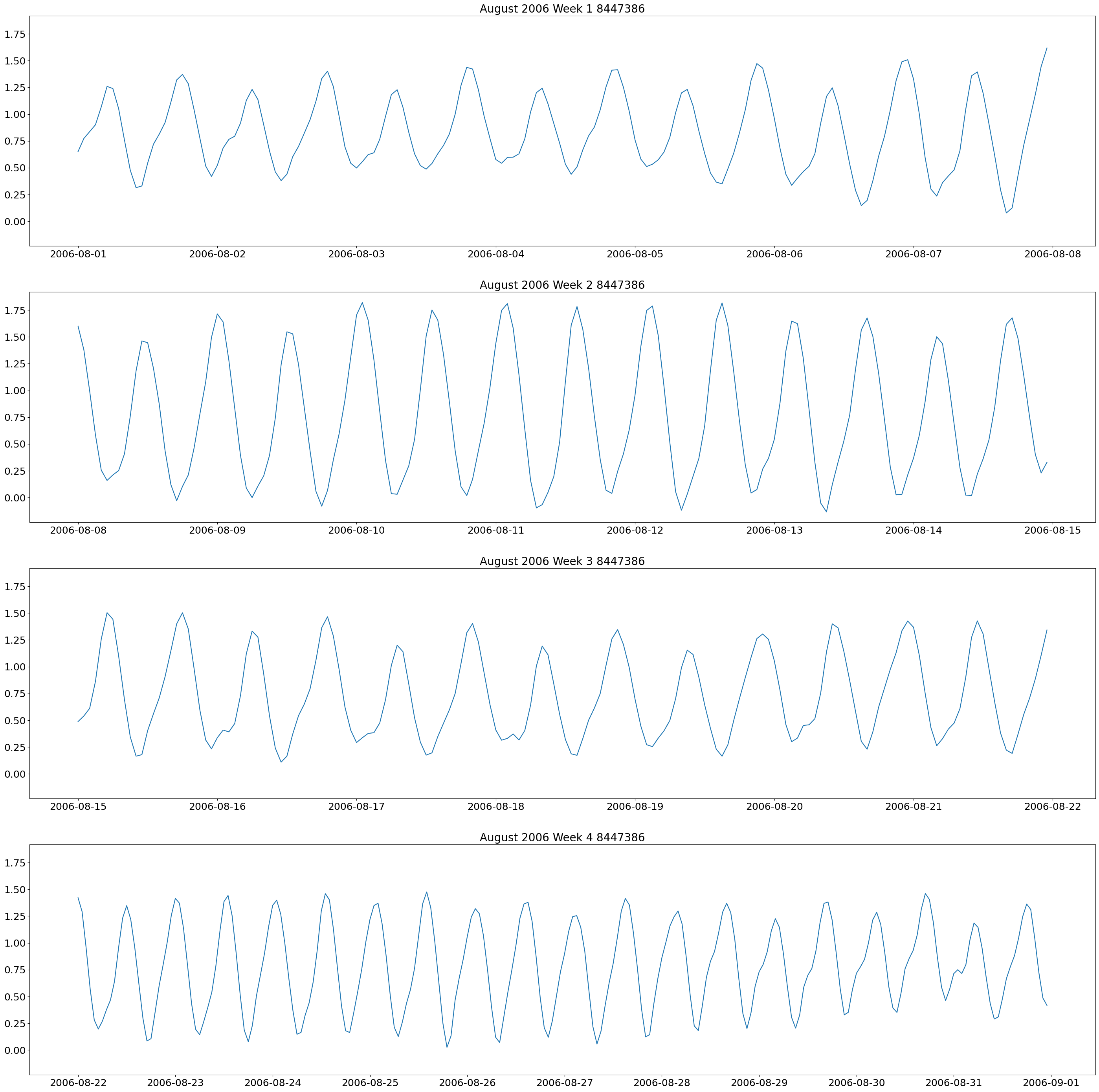
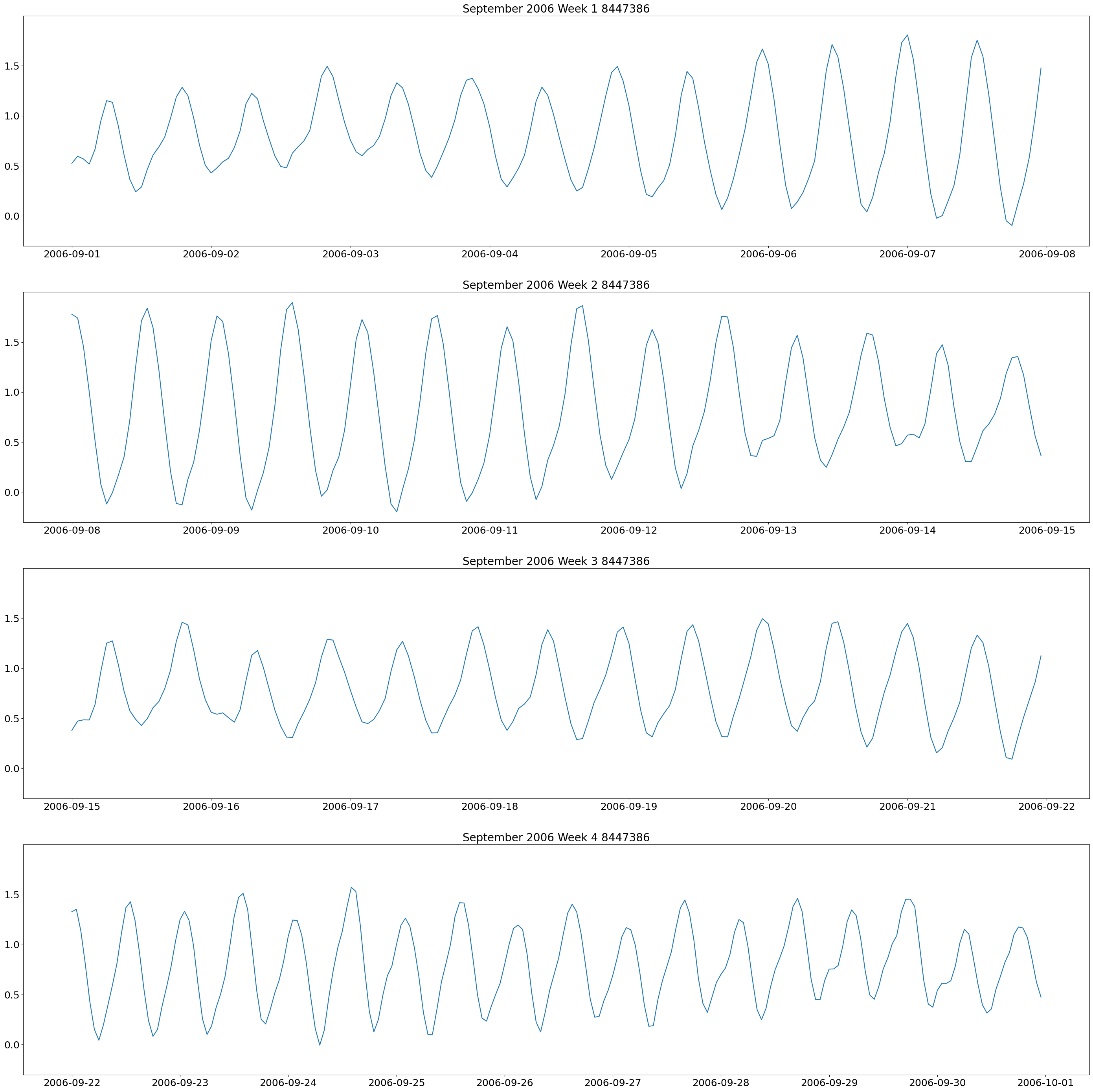
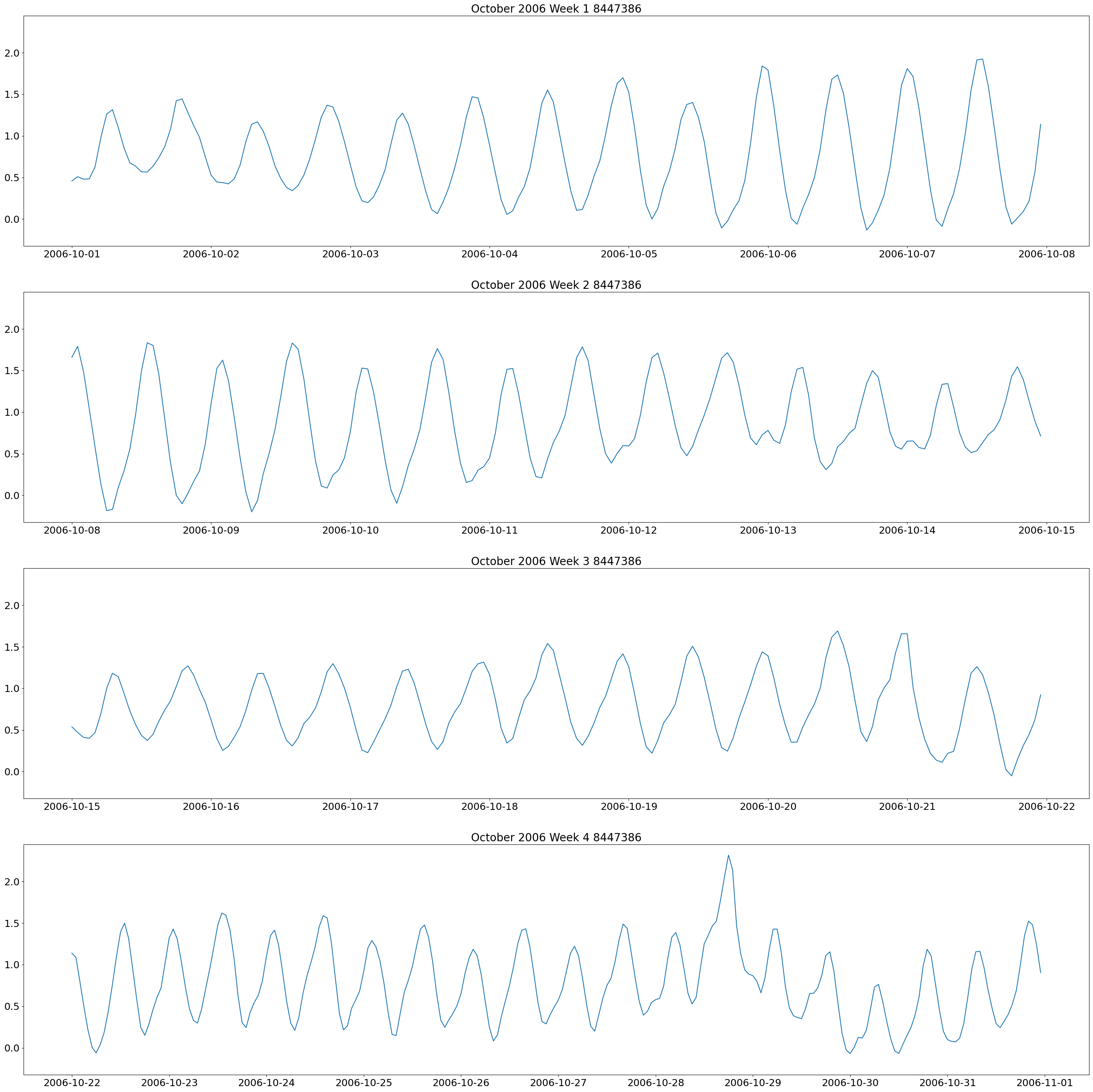
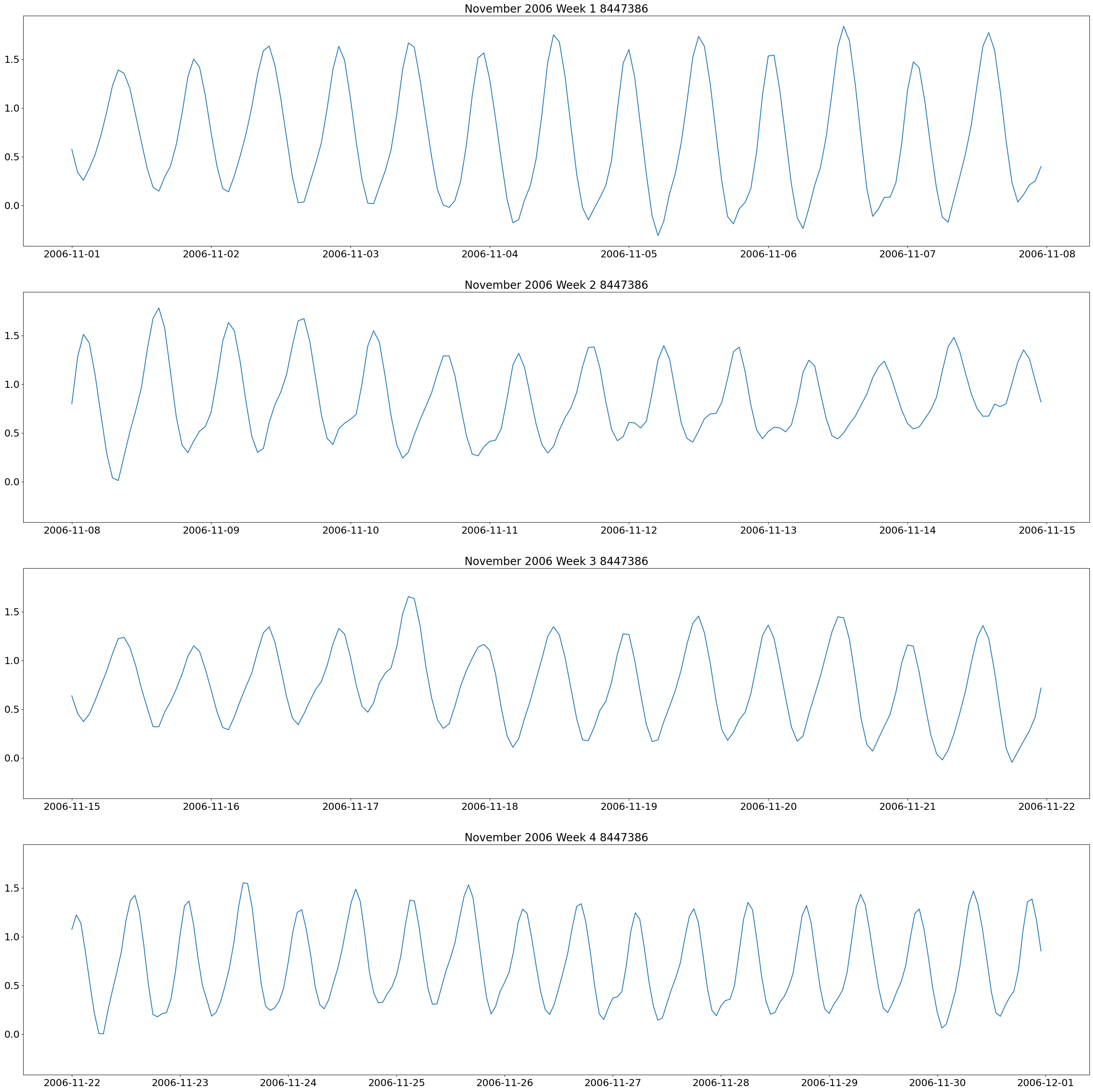
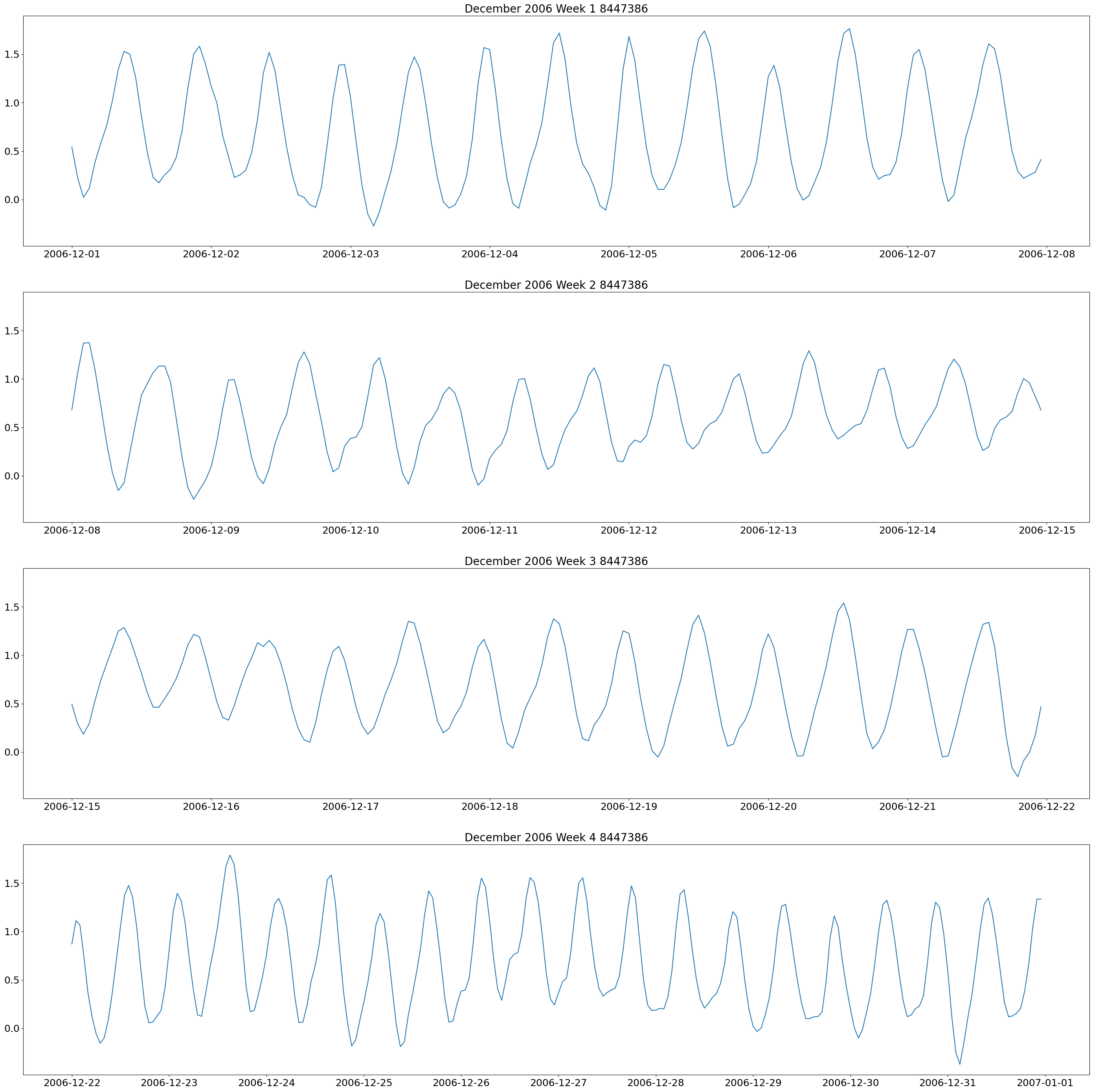
These plots show two high and low tides per day, and you can also see how the tides change throughout the month.
Similar weekly subplots can be made, but where each station is on the same plot rather than one at a time.
#Define a function to make weekly lists
def weeklylist(time, water_level, year, month):
#Create a list where it ends in only the year you want
yr=[]
yr_level=[]
for k in range(len(time)):
if year in time[k]:
yr.append(time[k])
yr_level.append(water_level[k])
#Creat a list where the first part of the string is the month you want to only get that month
mmyr=[]
mmyr_water_str=[]
for i in range(len(yr)):
if yr[i].startswith(month):
mmyr.append(yr[i])
mmyr_water_str.append(yr_level[i])
week1_str=[]
week1_water_str=[]
week2_str=[]
week2_water_str=[]
week3_str=[]
week3_water_str=[]
week4_str=[]
week4_water_str=[]
for j in range(len(mmyr)):
#Say that if the date contains these days in the middle, that is week one. So days 1 through 7
if "/1/" in mmyr[j] or "/2/" in mmyr[j] or "/3/" in mmyr[j] or "/4/" in mmyr[j] or "/5/" in mmyr[j] or "/6/" in mmyr[j] or "/7/" in mmyr[j]:
week1_str.append(mmyr[j])
week1_water_str.append(mmyr_water_str[j])
#Days 8 through 14 are week 2
elif "/8/" in mmyr[j] or "/9/" in mmyr[j] or "/10/" in mmyr[j] or "/11/" in mmyr[j] or "/12/" in mmyr[j] or "/13/" in mmyr[j] or "/14/" in mmyr[j]:
week2_str.append(mmyr[j])
week2_water_str.append(mmyr_water_str[j])
#Days 15 through 21 are week 3
elif "/15/" in mmyr[j] or "/16/" in mmyr[j] or "/17/" in mmyr[j] or "/18/" in mmyr[j] or "/19/" in mmyr[j] or "/20/" in mmyr[j] or "/21/" in mmyr[j]:
week3_str.append(mmyr[j])
week3_water_str.append(mmyr_water_str[j])
#Days 22 through 31 are week 4
elif "/22/" in mmyr[j] or "/23/" in mmyr[j] or "/24/" in mmyr[j] or "/25/" in mmyr[j] or "/26/" in mmyr[j] or "/27/" in mmyr[j] or "/28/" in mmyr[j] or "/29/" in mmyr[j] or "/30/" in mmyr[j] or "/31/" in mmyr[j]:
week4_str.append(mmyr[j])
week4_water_str.append(mmyr_water_str[j])
#Make the list of string dates into datetime
week1=[]
week2=[]
week3=[]
week4=[]
for l in range(len(week1_str)):
week1.append(datetime.strptime(week1_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week2_str)):
week2.append(datetime.strptime(week2_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week3_str)):
week3.append(datetime.strptime(week3_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week4_str)):
week4.append(datetime.strptime(week4_str[l], '%m/%d/%Y %H:%M'))
#Make the list of weekly water level strings into floats
week1_water=[]
week2_water=[]
week3_water=[]
week4_water=[]
for i in range(len(week1_water_str)):
week1_water.append(float(week1_water_str[i]))
for i in range(len(week2_water_str)):
week2_water.append(float(week2_water_str[i]))
for i in range(len(week3_water_str)):
week3_water.append(float(week3_water_str[i]))
for i in range(len(week4_water_str)):
week4_water.append(float(week4_water_str[i]))
return week1, week1_water, week2, week2_water, week3, week3_water, week4, week4_water
#Making a plot to compare weekly water level of all buoys for May 2018
#First make all of the weekly data lists
week1_8447386, week1water_8447386, week2_8447386, week2water_8447386, week3_8447386, week3water_8447386, week4_8447386, week4water_8447386=weeklylist(time_8447386, water_8447386, "/2018", "5/")
week1_8447930, week1water_8447930, week2_8447930, week2water_8447930, week3_8447930, week3water_8447930, week4_8447930, week4water_8447930=weeklylist(time_8447930, water_8447930, "/2018", "5/")
week1_8449130, week1water_8449130, week2_8449130, week2water_8449130, week3_8449130, week3water_8449130, week4_8449130, week4water_8449130=weeklylist(time_8449130, water_8449130, "/2018", "5/")
week1_8452660, week1water_8452660, week2_8452660, week2water_8452660, week3_8452660, week3water_8452660, week4_8452660, week4water_8452660=weeklylist(time_8452660, water_8452660, "/2018", "5/")
week1_8452944, week1water_8452944, week2_8452944, week2water_8452944, week3_8452944, week3water_8452944, week4_8452944, week4water_8452944=weeklylist(time_8452944, water_8452944, "/2018", "5/")
week1_8454000, week1water_8454000, week2_8454000, week2water_8454000, week3_8454000, week3water_8454000, week4_8454000, week4water_8454000=weeklylist(time_8454000, water_8454000, "/2018", "5/")
week1_8454049, week1water_8454049, week2_8454049, week2water_8454049, week3_8454049, week3water_8454049, week4_8454049, week4water_8454049=weeklylist(time_8454049, water_8454049, "/2018", "5/")
week1_8461490, week1water_8461490, week2_8461490, week2water_8461490, week3_8461490, week3water_8461490, week4_8461490, week4water_8461490=weeklylist(time_8461490, water_8461490, "/2018", "5/")
week1_8510560, week1water_8510560, week2_8510560, week2water_8510560, week3_8510560, week3water_8510560, week4_8510560, week4water_8510560=weeklylist(time_8510560, water_8510560, "/2018", "5/")
#Start making subplots of the 4 weeks
fig, axs=plt.subplots(4, figsize=(35,35), sharey = True)
#Lines for the first week
axs[0].plot(week1_8447386, week1water_8447386, label="8447386", color='red')
axs[0].plot(week1_8447386, week1water_8447930, label="8447930", color='blue')
axs[0].plot(week1_8447386, week1water_8449130, label="8449130", color='cyan' )
axs[0].plot(week1_8447386, week1water_8452660, label="8452660", color='coral')
axs[0].plot(week1_8447386, week1water_8452944, label="8452944", color='purple')
axs[0].plot(week1_8447386, week1water_8454000, label="8454000", color='limegreen')
axs[0].plot(week1_8447386, week1water_8454049, label="8454049", color='black')
axs[0].plot(week1_8447386, week1water_8461490, label="8461490", color='brown')
axs[0].plot(week1_8447386, week1water_8510560, label="8510560", color='yellow')
#Lines for the second week
axs[1].plot(week1_8447386, week2water_8447386, label="8447386", color='red')
axs[1].plot(week1_8447386, week2water_8447930, label="8447930", color='blue')
axs[1].plot(week1_8447386, week2water_8449130, label="8449130", color='cyan')
axs[1].plot(week1_8447386, week2water_8452660, label="8452660", color='coral')
axs[1].plot(week1_8447386, week2water_8452944, label="8452944", color='purple')
axs[1].plot(week1_8447386, week2water_8454000, label="8454000", color='limegreen')
axs[1].plot(week1_8447386, week2water_8454049, label="8454049", color='black')
axs[1].plot(week1_8447386, week2water_8461490, label="8461490", color='brown')
axs[1].plot(week1_8447386, week2water_8510560, label="8510560", color='yellow')
#Week 3
axs[2].plot(week1_8447386, week3water_8447386, label="8447386", color='red')
axs[2].plot(week1_8447386, week3water_8447930, label="8447930", color='blue')
axs[2].plot(week1_8447386, week3water_8449130, label="8449130", color='cyan')
axs[2].plot(week1_8447386, week3water_8452660, label="8452660", color='coral')
axs[2].plot(week1_8447386, week3water_8452944, label="8452944", color='purple')
axs[2].plot(week1_8447386, week3water_8454000, label="8454000", color='limegreen')
axs[2].plot(week1_8447386, week3water_8454049, label="8454049", color='black')
axs[2].plot(week1_8447386, week3water_8461490, label="8461490", color='brown')
axs[2].plot(week1_8447386, week3water_8510560, label="8510560", color='yellow')
#Week 4
axs[3].plot(week4_8447386, week4water_8447386, label="8447386", color='red')
axs[3].plot(week4_8447386, week4water_8447930, label="8447930", color='blue')
axs[3].plot(week4_8447386, week4water_8449130, label="8449130", color='cyan')
axs[3].plot(week4_8447386, week4water_8452660, label="8452660", color='coral')
axs[3].plot(week4_8447386, week4water_8452944, label="8452944", color='purple')
axs[3].plot(week4_8447386, week4water_8454000, label="8454000", color='limegreen')
axs[3].plot(week4_8447386, week4water_8454049, label="8454049", color='black')
axs[3].plot(week4_8447386, week4water_8461490, label="8461490", color='brown')
axs[3].plot(week4_8447386, week4water_8510560, label="8510560", color='yellow')
#Making title of each plot
axs[0].set_title("Week 1 May 2018", fontsize=20)
axs[1].set_title("Week 2 May 2018", fontsize=20)
axs[2].set_title("Week 3 May 2018", fontsize=20)
axs[3].set_title("Week 4 May 2018", fontsize=20)
#Setting font of the axes
axs[0].xaxis.set_tick_params(labelsize=18)
axs[1].xaxis.set_tick_params(labelsize=18)
axs[2].xaxis.set_tick_params(labelsize=18)
axs[3].xaxis.set_tick_params(labelsize=18)
axs[0].yaxis.set_tick_params(labelsize=18)
axs[1].yaxis.set_tick_params(labelsize=18)
axs[2].yaxis.set_tick_params(labelsize=18)
axs[3].yaxis.set_tick_params(labelsize=18)
plt.legend()
<matplotlib.legend.Legend at 0x2b1e4fc70>
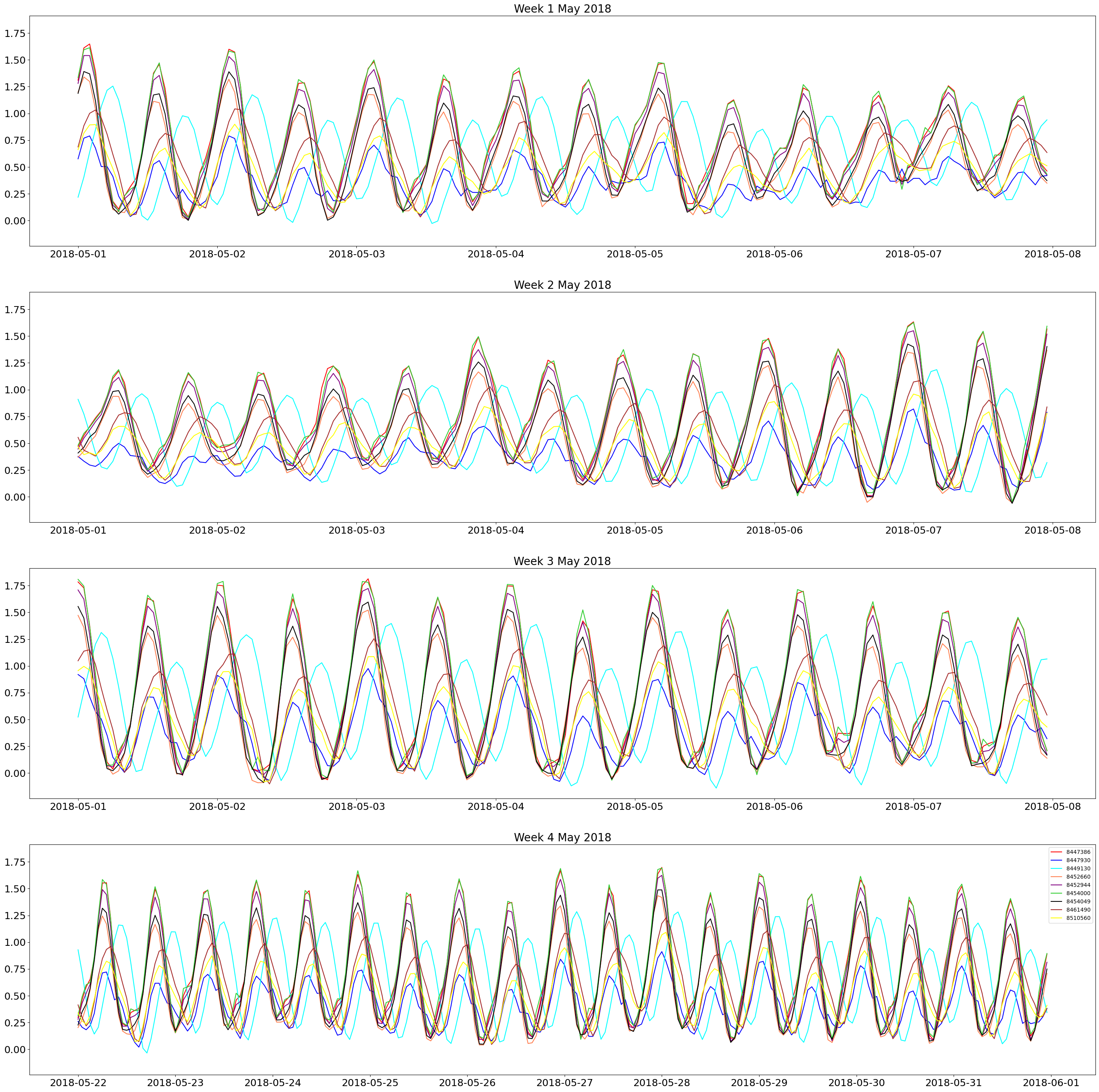
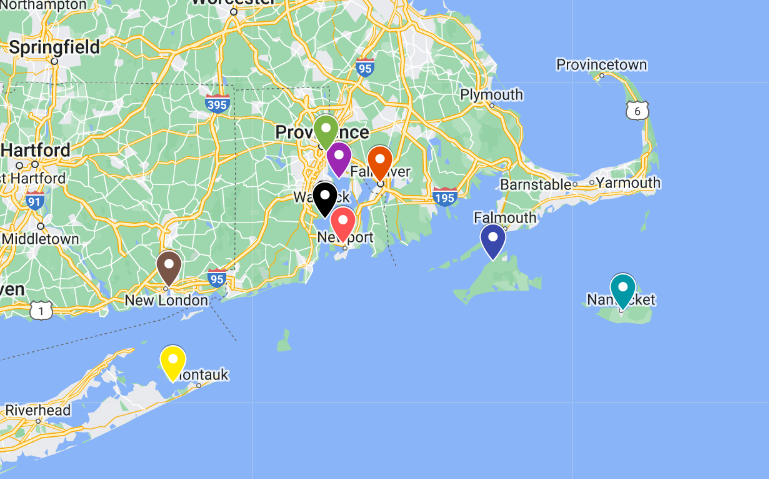
The plot is the one above. The colors of each line correspond to the map of the buoys above. It can be seen that the 4 tide gauges that are farther into the ocean (8449130, 8447930, 8510560, 8461490) have a lower overall amplitude of water level, which corresponds to known tidal behavior. The tide gauges that are closer together and directly in the bay have higher peaks that tend to peak around the same time. It can also be seen that the water level peaks move in a counterclockwise direction.
We can also make these weekly subplots, but compare the verified NOAA water level to the predicted NOAA water level. This would be interesting to see in the events of storms and heavy rain. There would be a large difference between the predicted and verified water level in such an event because the predicted ones do not predict storms. By comparing the two in a line graph, we can visualize the storm surge.
def predictedvsverified(time, waterlevel_verified, waterlevel_predicted, year, month, title1, title2, title3, title4, file):
#Create a list where it ends in only the year you want for predicted and verified data
yr=[]
yrp_level=[]
yrv_level=[]
for k in range(len(time)):
if year in time[k]:
yr.append(time[k])
yrp_level.append(waterlevel_predicted[k])
yrv_level.append(waterlevel_verified[k])
#Creat a list where the first part of the string is the month you want to only get that month
mmyr=[]
mmyr_waterp_str=[]
mmyr_waterv_str=[]
for i in range(len(yr)):
if yr[i].startswith(month):
mmyr.append(yr[i])
mmyr_waterp_str.append(yrp_level[i])
mmyr_waterv_str.append(yrv_level[i])
#Make weekly lists for that month of predicted and verified data
week1_str=[]
week1_waterp_str=[]
week1_waterv_str=[]
week2_str=[]
week2_waterp_str=[]
week2_waterv_str=[]
week3_str=[]
week3_waterp_str=[]
week3_waterv_str=[]
week4_str=[]
week4_waterp_str=[]
week4_waterv_str=[]
for j in range(len(mmyr)):
#Say that if the date contains these days in the middle, that is week one. So days 1 through 7
if "/1/" in mmyr[j] or "/2/" in mmyr[j] or "/3/" in mmyr[j] or "/4/" in mmyr[j] or "/5/" in mmyr[j] or "/6/" in mmyr[j] or "/7/" in mmyr[j]:
week1_str.append(mmyr[j])
week1_waterp_str.append(mmyr_waterp_str[j])
week1_waterv_str.append(mmyr_waterv_str[j])
#Days 8 through 14 are week 2
elif "/8/" in mmyr[j] or "/9/" in mmyr[j] or "/10/" in mmyr[j] or "/11/" in mmyr[j] or "/12/" in mmyr[j] or "/13/" in mmyr[j] or "/14/" in mmyr[j]:
week2_str.append(mmyr[j])
week2_waterp_str.append(mmyr_waterp_str[j])
week2_waterv_str.append(mmyr_waterv_str[j])
#Days 15 through 21 are week 3
elif "/15/" in mmyr[j] or "/16/" in mmyr[j] or "/17/" in mmyr[j] or "/18/" in mmyr[j] or "/19/" in mmyr[j] or "/20/" in mmyr[j] or "/21/" in mmyr[j]:
week3_str.append(mmyr[j])
week3_waterp_str.append(mmyr_waterp_str[j])
week3_waterv_str.append(mmyr_waterv_str[j])
#Days 22 through 31 are week 4
elif "/22/" in mmyr[j] or "/23/" in mmyr[j] or "/24/" in mmyr[j] or "/25/" in mmyr[j] or "/26/" in mmyr[j] or "/27/" in mmyr[j] or "/28/" in mmyr[j] or "/29/" in mmyr[j] or "/30/" in mmyr[j] or "/31/" in mmyr[j]:
week4_str.append(mmyr[j])
week4_waterp_str.append(mmyr_waterp_str[j])
week4_waterv_str.append(mmyr_waterv_str[j])
#Make the list of string dates into datetime
week1=[]
week2=[]
week3=[]
week4=[]
for l in range(len(week1_str)):
week1.append(datetime.strptime(week1_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week2_str)):
week2.append(datetime.strptime(week2_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week3_str)):
week3.append(datetime.strptime(week3_str[l], '%m/%d/%Y %H:%M'))
for l in range(len(week4_str)):
week4.append(datetime.strptime(week4_str[l], '%m/%d/%Y %H:%M'))
#Make the list of weekly water level strings into floats
week1_waterp=[]
week2_waterp=[]
week3_waterp=[]
week4_waterp=[]
week1_waterv=[]
week2_waterv=[]
week3_waterv=[]
week4_waterv=[]
for i in range(len(week1_waterp_str)):
week1_waterp.append(float(week1_waterp_str[i]))
week1_waterv.append(float(week1_waterv_str[i]))
for i in range(len(week2_waterp_str)):
week2_waterp.append(float(week2_waterp_str[i]))
week2_waterv.append(float(week2_waterv_str[i]))
for i in range(len(week3_waterp_str)):
week3_waterp.append(float(week3_waterp_str[i]))
week3_waterv.append(float(week3_waterv_str[i]))
for i in range(len(week4_waterp_str)):
week4_waterp.append(float(week4_waterp_str[i]))
week4_waterv.append(float(week4_waterv_str[i]))
#Making subplots. I want 4 vertical plots and for them to share a y-axis
fig, axs=plt.subplots(4, figsize=(35,35), sharey = True)
axs[0].plot(week1, week1_waterp, label="Predicted", color="lightpink")
axs[0].plot(week1, week1_waterv, label="Verified", color="blue")
axs[1].plot(week2, week2_waterp, label="Predicted", color="lightpink")
axs[1].plot(week2, week2_waterv, label="Verified", color="blue")
axs[2].plot(week3, week3_waterp, label="Predicted", color="lightpink")
axs[2].plot(week3, week3_waterv, label="Verified", color="blue")
axs[3].plot(week4, week4_waterp, label="Predicted", color="lightpink")
axs[3].plot(week4, week4_waterv, label="Verified", color="blue")
#Making title of each plot
axs[0].set_title(title1, fontsize=20)
axs[1].set_title(title2, fontsize=20)
axs[2].set_title(title3, fontsize=20)
axs[3].set_title(title4, fontsize=20)
#Setting font of the axes
axs[0].xaxis.set_tick_params(labelsize=18)
axs[1].xaxis.set_tick_params(labelsize=18)
axs[2].xaxis.set_tick_params(labelsize=18)
axs[3].xaxis.set_tick_params(labelsize=18)
axs[0].yaxis.set_tick_params(labelsize=18)
axs[1].yaxis.set_tick_params(labelsize=18)
axs[2].yaxis.set_tick_params(labelsize=18)
axs[3].yaxis.set_tick_params(labelsize=18)
plt.legend()
#plt.show
plt.savefig(file)
#Making plots of predicted versus verified water level during the month of Hurricane Henri for station 8510560
predictedvsverified(time_8510560, water_8510560, predicted_8510560, "/2021", "8/", "Hurricane Henri Week 1", "Hurricane Henri Week 2", "Hurricane Henri Week 3", "Hurricane Henri Week 4", f'{plots_dir}tide_plots/Hurricane_Henri_8510560.png')
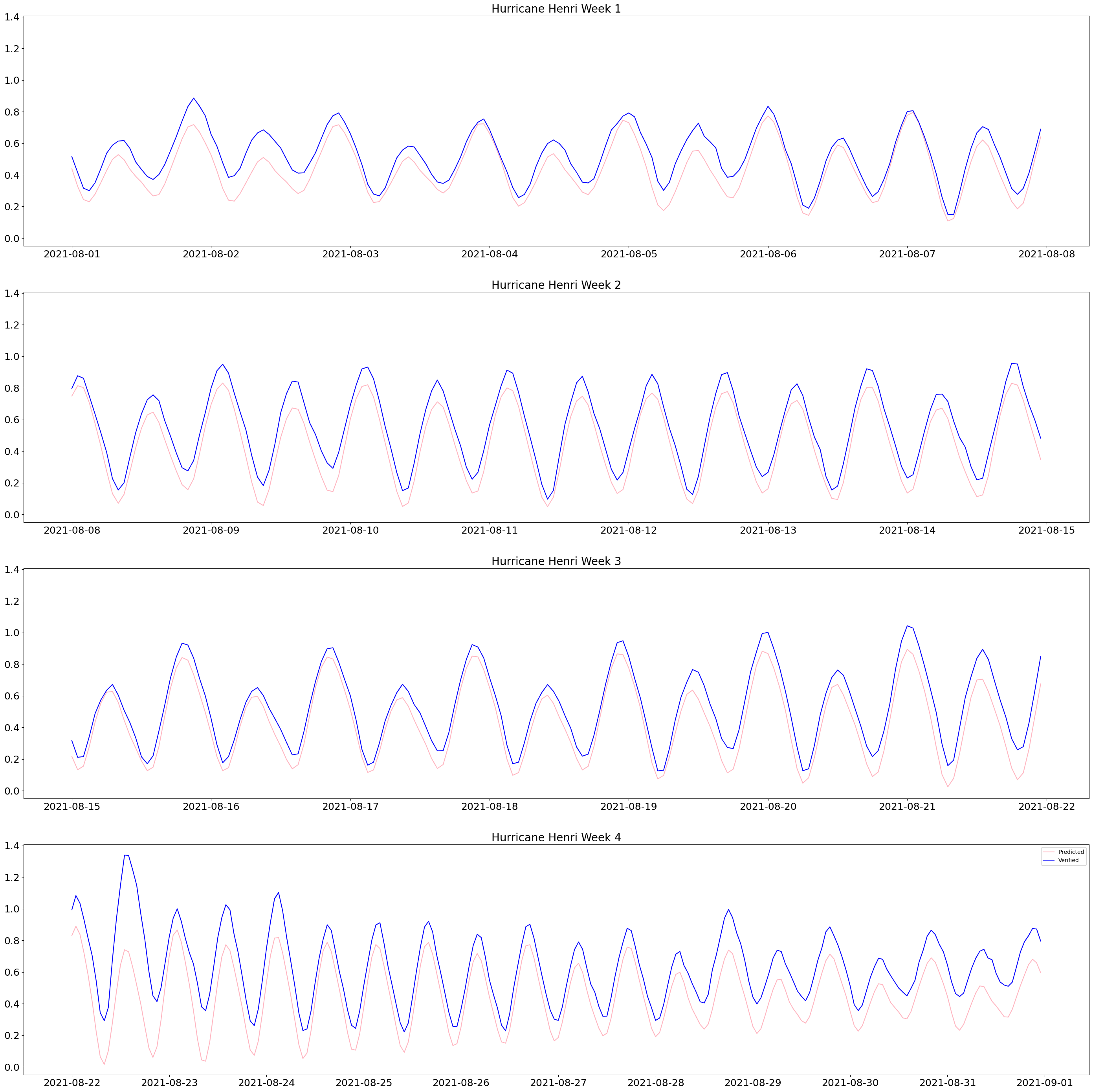
The plots above are the result of that code. Hurricane Henri occurred towards the end of August 2018. You can see the verified water level is a lot higher than the predicted starting from August 22, 2021.
For the OSOM data, we are largely concerned with analyzing how accurately the model predicts the observed water level. The first step in this is to read in the OSOM data. This data is stored in a netCDF file, so it needs a different function than the comma-separated value data. We have two different versions of the OSOM water level data, version 000 and version 001. We must read in the files for each tide gauge location, and also for each version. Version 000 is based on NOAA 2003 tide data while version 001 is based on NOAA 2015 information.
#"file" is the location of the netCDF files
def readnc(file):
#Read in the netCDF file
f=nc.Dataset(file)
#Define the variabels we want, zeta and time
zeta0 = f.variables['zeta']
ocean_time = f.variables['ocean_time']
#Read in the zeta variable
Zeta=zeta0[:]
#Reshape it so it is only 1 dimension and plottable
Zeta=Zeta.reshape(-1,)
#Turn the array into a list so it is easy to plot and manipulate
zeta=Zeta.tolist()
#Convert the time from seconds since 01-01-2017 to dates
dates = num2date(ocean_time[:], ocean_time.units)
return zeta, dates
#Read in the file for each station for version 000
zeta_8447930_000, date_8447930_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_BZBM3.nc')
zeta_8452944_000, date_8452944_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_CPTR1.nc')
zeta_8454000_000, date_8454000_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_FOXR1.nc')
zeta_8447386_000, date_8447386_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_FRVM3.nc')
zeta_8510560_000, date_8510560_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_MTKN6.nc')
zeta_8461490_000, date_8461490_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_NLNC3.nc')
zeta_8449130_000, date_8449130_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_NTKM3.nc')
zeta_8452660_000, date_8452660_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_NWPR1.nc')
zeta_8454049_000, date_8454049_000=readnc(f'{raw_data_dir}osom_tides/tides_000/tide_QPTR1.nc')
#Read in the file for each station for version 001
zeta_8447930_001, date_8447930_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_BZBM3.nc')
zeta_8452944_001, date_8452944_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_CPTR1.nc')
zeta_8454000_001, date_8454000_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_FOXR1.nc')
zeta_8447386_001, date_8447386_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_FRVM3.nc')
zeta_8510560_001, date_8510560_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_MTKN6.nc')
zeta_8461490_001, date_8461490_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_NLNC3.nc')
zeta_8449130_001, date_8449130_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_NTKM3.nc')
zeta_8452660_001, date_8452660_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_NWPR1.nc')
zeta_8454049_001, date_8454049_001=readnc(f'{raw_data_dir}osom_tides/tides_001/tide_QPTR1.nc')
The OSOM water level data is the average over an hour, not an instantaneous point. The NOAA data is an instantaneous measurement at that time. So, in order to compare the two, we need to average the NOAA data over an hour. For this purpose, we use the 6 minute data instead of the hourly data. The average is taken around the center of the hour. For example, the average of from 01:00 to 01:54.
def averages(time_noaa, waterlevel_noaa):
time30=[]
averagecenter=[]
for i in range(len(time_noaa)):
if "/2017" in time_noaa[i]:
listcenter=[]
if ":30" in time_noaa[i]:
time30.append(time_noaa[i])
listcenter.append(waterlevel_noaa[i-5])
listcenter.append(waterlevel_noaa[i-4])
listcenter.append(waterlevel_noaa[i-3])
listcenter.append(waterlevel_noaa[i-2])
listcenter.append(waterlevel_noaa[i-1])
listcenter.append(waterlevel_noaa[i])
listcenter.append(waterlevel_noaa[i+1])
listcenter.append(waterlevel_noaa[i+2])
listcenter.append(waterlevel_noaa[i+3])
listcenter.append(waterlevel_noaa[i+4])
averagecenter.append(np.nanmean(listcenter))
return time30, averagecenter
#Read in the 6 minute interval csv files
time_8447386_avg, water_8447386_avg, predicted_8447386_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8447386_average.csv')
time_8447930_avg, water_8447930_avg, predicted_8447930_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8447930_average.csv')
time_8449130_avg, water_8449130_avg, predicted_8449130_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8449130_average.csv')
time_8452660_avg, water_8452660_avg, predicted_8452660_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8452660_average.csv')
time_8452944_avg, water_8452944_avg, predicted_8452944_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8452944_average.csv')
time_8454000_avg, water_8454000_avg, predicted_8454000_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8454000_average.csv')
time_8454049_avg, water_8454049_avg, predicted_8454049_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8454049_average.csv')
time_8461490_avg, water_8461490_avg, predicted_8461490_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8461490_average.csv')
time_8510560_avg, water_8510560_avg, predicted_8510560_avg = readcsv(f'{raw_data_dir}tides/average/CO-OPS_8510560_average.csv')
#Call the function to make the lists of average values
time_8447386_30, water_8447386_center=averages(time_8447386_avg, water_8447386_avg)
time_8447930_30, water_8447930_center=averages(time_8447930_avg, water_8447930_avg)
time_8449130_30, water_8449130_center=averages(time_8449130_avg, water_8449130_avg)
time_8452660_30, water_8452660_center=averages(time_8452660_avg, water_8452660_avg)
time_8452944_30, water_8452944_center=averages(time_8452944_avg, water_8452944_avg)
time_8454000_30, water_8454000_center=averages(time_8454000_avg, water_8454000_avg)
time_8454049_30, water_8454049_center=averages(time_8454049_avg, water_8454049_avg)
time_8461490_30, water_8461490_center=averages(time_8461490_avg, water_8461490_avg)
time_8510560_30, water_8510560_center=averages(time_8510560_avg, water_8510560_avg)
/var/folders/0y/r_pk_m1j77vbq82t895ph8780000gq/T/ipykernel_45295/2111228112.py:19: RuntimeWarning: Mean of empty slice
averagecenter.append(np.nanmean(listcenter))
To assess the accuracy of the model, we can make scatterplots where the observed water level values are on the x-axis and the modeled values are on the y-axis. Then we can see how close the data is to a one-to-one relationship. For this and all future analysis, a correction is made because the NOAA water level is calculated with respect to mean low low water (MLLW), but OSOM is not. To account for this, we average both the NOAA water levels for that station in 2017 and the OSOM water levels. Then take the difference of the averages and add that to each value in the OSOM water level list.
#"average_noaa" is the list of NOAA water level data that we averaged over the hour
#"osom_000" is the OSOM version 000 water level list
#"osom_001" is the OSOM version 001 water level list
#"title" is what you want to call the plot
#"path" is where you want to save the plot
def averagescatterplots(average_noaa, osom_000, osom_001, title, path):
#Model 001 does not include 12/31/17, so delete the last 24 hours of the NOAA data
average_noaa_001=[]
for i in range(len(average_noaa)):
average_noaa_001.append(average_noaa[i])
del average_noaa_001[-24:]
#Remove data that are nan values
new_buoy_000 = []
new_zeta_000=[]
for i in range(len(average_noaa)):
if str(average_noaa[i]) != 'nan':
new_buoy_000.append(average_noaa[i])
new_zeta_000.append(osom_000[i])
new_buoy_001 = []
new_zeta_001=[]
for i in range(len(average_noaa_001)):
if str(average_noaa_001[i]) != 'nan':
new_buoy_001.append(average_noaa_001[i])
new_zeta_001.append(osom_001[i])
#Find the average of the NOAA data and the OSOM data
average_noaa_000=sum(new_buoy_000)/len(new_buoy_000)
average_osom_000=sum(new_zeta_000)/len(new_zeta_000)
#NOAA data is taken with respect to MLLW and OSOM is not
#To correct this difference, we will take the difference between the averages and add it to the OSOM data
difference_000=average_noaa_000-average_osom_000
corrected_000=[]
for j in range(len(new_zeta_000)):
corrected_000.append(new_zeta_000[j]+difference_000)
average_noaa_001=sum(new_buoy_001)/len(new_buoy_001)
average_osom_001=sum(new_zeta_001)/len(new_zeta_001)
difference_001=average_noaa_001-average_osom_001
corrected_001=[]
for j in range(len(new_zeta_001)):
corrected_001.append(new_zeta_001[j]+difference_001)
#Now make the scatterplot. Two subplots to compare side-by-side
fig, axes = plt.subplots(1, 2, figsize=(12, 6), sharex=True, sharey=True)
axes[0].scatter(new_buoy_000, corrected_000)
xpoints_000 = ypoints_000 = plt.xlim()
#This is line y=x
axes[0].plot(xpoints_000, ypoints_000, color='k', lw=3, scalex=False, scaley=False)
#This is the slope of the scatter points
axes[0].plot(np.unique(new_buoy_000), np.poly1d(np.polyfit(new_buoy_000, corrected_000, 1))(np.unique(new_buoy_000)), linestyle='--', lw=3, color='red')
axes[1].scatter(new_buoy_001, corrected_001)
xpoints_001 = ypoints_001 = plt.xlim()
#This is line y=x
axes[1].plot(xpoints_001, ypoints_001, color='k', lw=3, scalex=False, scaley=False)
#This is the slope of the scatter points
axes[1].plot(np.unique(new_buoy_001), np.poly1d(np.polyfit(new_buoy_001, corrected_001, 1))(np.unique(new_buoy_001)), linestyle='--', lw=3, color='red')
axes[0].set_title("000")
axes[1].set_title("001")
fig.text(0.5, 0.04, 'Observed Water Level (m)', ha='center', va='center')
fig.text(0.06, 0.5, 'Modeled Water Level (m)', ha='center', va='center', rotation='vertical')
plt.suptitle(title)
plt.savefig(path)
#Use the function to produce an example for the Wood's Hole Station (8447930)
averagescatterplots(water_8447930_center, zeta_8447930_000, zeta_8447930_001, 'Observed vs Modeled 8447930', f'{plots_dir}/avg_scatter_woodshole.png')
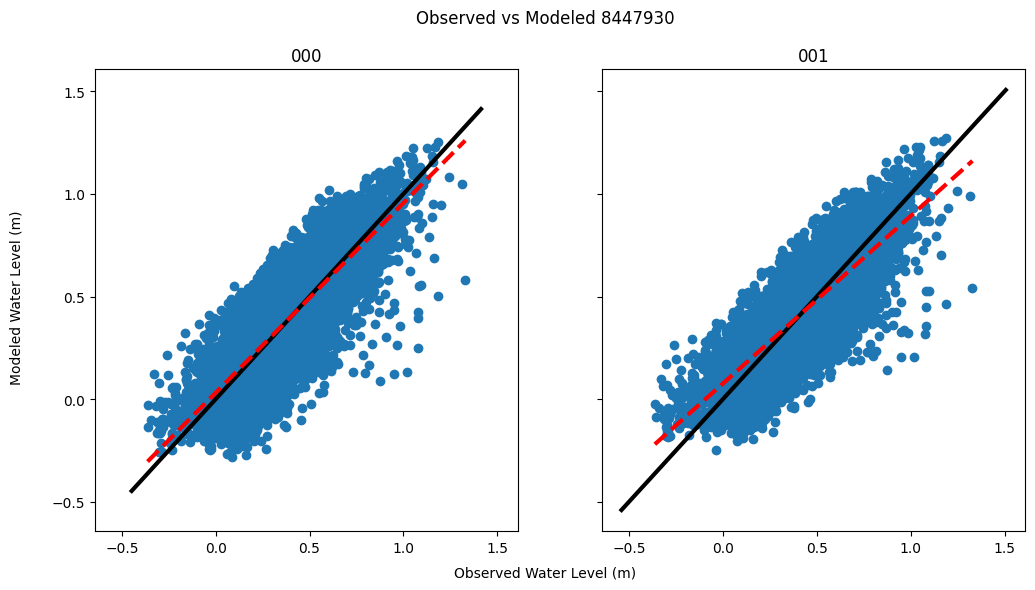
The plot above is an example for station 8447930. The black line represents a perfect one-to-one relationship. The red dotted line represents the actual line of best fit. We can see that the two do not match, for either version of the model. This hints towards necessary corrections.
To quantify how much each station should be corrected, we can calculate scale (slope), bias (intercept), and standard error. For scale and slope, we use a function that already exists in numpy. For the standard error, we calculate two types: raw and corrected. The raw standard error is the error of the difference between the observed and modeled water level. The corrected standard error is the error of the difference between the observed water level and the modeled water level multiplied by scale and added by bias. According to these values, it was found overall that Modeled = (86%-96%)* +/- (15%-18%). The code to find these values is below.
#Make a function to return slope and intercepts of the lines and compare
#"average_noaa" is the list of NOAA water level data that we averaged over the hour
#"osom_000" is the OSOM version 000 water level list
#"osom_001" is the OSOM version 001 water level list
def slope(average_noaa, osom_000, osom_001):
#Model 001 does not include 12/31/17, so delete the last 24 hours of the NOAA data
average_noaa_001=[]
for i in range(len(average_noaa)):
average_noaa_001.append(average_noaa[i])
del average_noaa_001[-24:]
#Remove data that are nan values
new_buoy_000=[]
new_zeta_000=[]
for i in range(len(average_noaa)):
if str(average_noaa[i]) != 'nan':
new_buoy_000.append(average_noaa[i])
new_zeta_000.append(osom_000[i])
new_buoy_001=[]
new_zeta_001=[]
for i in range(len(average_noaa_001)):
if str(average_noaa_001[i]) != 'nan':
new_buoy_001.append(average_noaa_001[i])
new_zeta_001.append(osom_001[i])
#Find the average of the NOAA data and the OSOM data
average_noaa_000=sum(new_buoy_000)/len(new_buoy_000)
average_osom_000=sum(new_zeta_000)/len(new_zeta_000)
#NOAA data is taken with respect to MLLW and OSOM is not
#To correct this difference, we will take the difference between the averages and add it to the OSOM data
difference_000=average_noaa_000-average_osom_000
corrected_000=[]
for j in range(len(new_zeta_000)):
corrected_000.append(new_zeta_000[j]+difference_000)
average_noaa_001=sum(new_buoy_001)/len(new_buoy_001)
average_osom_001=sum(new_zeta_001)/len(new_zeta_001)
difference_001=average_noaa_001-average_osom_001
corrected_001=[]
for j in range(len(new_zeta_001)):
corrected_001.append(new_zeta_001[j]+difference_001)
slope_000, intercept_000 = np.polyfit(new_buoy_000,corrected_000,1)
slope_001, intercept_001 = np.polyfit(new_buoy_001,corrected_001,1)
return slope_000, slope_001, intercept_000, intercept_001
#Calculate the slope of the scatter plots at each station for center average
#slope_000_8447386, slope_001_8447386, int_000_8447386, int_001_8447386=slope(water_8447386_center, zeta_8447386_000, zeta_8447386_001)
slope_000_8447930, slope_001_8447930, int_000_8447930, int_001_8447930=slope(water_8447930_center, zeta_8447930_000, zeta_8447930_001)
#slope_000_8449130, slope_001_8449130, int_000_8449130, int_001_8449130=slope(water_8449130_center, zeta_8449130_000, zeta_8449130_001)
slope_000_8452660, slope_001_8452660, int_000_8452660, int_001_8452660=slope(water_8452660_center, zeta_8452660_000, zeta_8452660_001)
slope_000_8452944, slope_001_8452944, int_000_8452944, int_001_8452944=slope(water_8452944_center, zeta_8452944_000, zeta_8452944_001)
slope_000_8454000, slope_001_8454000, int_000_8454000, int_001_8454000=slope(water_8454000_center, zeta_8454000_000, zeta_8454000_001)
slope_000_8454049, slope_001_8454049, int_000_8454049, int_001_8454049=slope(water_8454049_center, zeta_8454049_000, zeta_8454049_001)
slope_000_8461490, slope_001_8461490, int_000_8461490, int_001_8461490=slope(water_8461490_center, zeta_8461490_000, zeta_8461490_001)
slope_000_8510560, slope_001_8510560, int_000_8510560, int_001_8510560=slope(water_8510560_center, zeta_8510560_000, zeta_8510560_001)
print("Slope 000 is", slope_000_8447930, slope_000_8452660, slope_000_8452944, slope_000_8454000, slope_000_8454049, slope_000_8461490, slope_000_8510560)
print("Slope 001 is", slope_001_8447930, slope_001_8452660, slope_001_8452944, slope_001_8454000, slope_001_8454049, slope_001_8461490, slope_001_8510560)
print("Intercept 000 is", int_000_8447930, int_000_8452660, int_000_8452944, int_000_8454000, int_000_8454049, int_000_8461490, int_000_8510560)
print("Intercept 001 is", int_001_8447930, int_001_8452660, int_001_8452944, int_001_8454000, int_001_8454049, int_001_8461490, int_001_8510560)
Slope 000 is 0.9248347932205239 0.8597591271816293 0.8641477866600545 0.8640915686692804 0.8651206476861524 0.9584189221606039 0.9000493769966204
Slope 001 is 0.8163607134844809 0.8492539838221369 0.8651276858463002 0.8699272561582342 0.858900650387783 0.9756947335039218 0.9289406713451425
Intercept 000 is 0.031173439533811652 0.08850902457130091 0.09871711317788315 0.10643142076920593 0.08771199507841519 0.024091530155163212 0.04989601063268159
Intercept 001 is 0.07621359158530411 0.09520143088200266 0.09806880756814369 0.10192676049829132 0.09181893682070112 0.014094336361984074 0.035496611375682025
#Write a function to return the raw standard deviation of the difference between observed and modeled data
def rawstdev(average_noaa, osom_000,osom_001):
#Model 001 does not include 12/31/17, so delete the last 24 hours of the NOAA data
average_noaa_001=[]
for i in range(len(average_noaa)):
average_noaa_001.append(average_noaa[i])
del average_noaa_001[-24:]
#Remove data that are nan values
new_buoy_000 = []
new_zeta_000 = []
for i in range(len(average_noaa)):
if str(average_noaa[i]) != 'nan':
new_buoy_000.append(average_noaa[i])
new_zeta_000.append(osom_000[i])
new_buoy_001 = []
new_zeta_001=[]
for i in range(len(average_noaa_001)):
if str(average_noaa_001[i]) != 'nan':
new_buoy_001.append(average_noaa_001[i])
new_zeta_001.append(osom_001[i])
#Find the average of the NOAA data and the OSOM data
average_noaa_000=np.nanmean(new_buoy_000)
average_osom_000=np.nanmean(new_zeta_000)
#NOAA data is taken with respect to MLLW and OSOM is not
#To correct this difference, we will take the difference between the averages and add it to the OSOM data
difference_000=average_noaa_000-average_osom_000
corrected_000=[]
for j in range(len(new_zeta_000)):
corrected_000.append(new_zeta_000[j]+difference_000)
average_noaa_001=np.nanmean(new_buoy_001)
average_osom_001=np.nanmean(new_zeta_001)
difference_001=average_noaa_001-average_osom_001
corrected_001=[]
for j in range(len(new_zeta_001)):
corrected_001.append(new_zeta_001[j]+difference_001)
#Calculate the differences of the observed vs modeled data for 000
differencelist_000=[]
for i in range(len(new_buoy_000)):
differencelist_000.append(new_buoy_000[i]-corrected_000[i])
#Calculate the differences of the observed vs modeled data 001
differencelist_001=[]
for k in range(len(new_buoy_001)):
differencelist_001.append(new_buoy_001[k]-corrected_001[k])
stdev_000=np.std(differencelist_000)
stdev_001=np.std(differencelist_001)
var_000=np.var(differencelist_000)
var_001=np.var(differencelist_001)
return stdev_000, stdev_001, var_000, var_001
#Calculate the raw standard error
#stdev_8447386_000, stdev_8447386_001, var_8447386_000, var_8447386_001=rawstdev(water_8447386_center, zeta_8447386_000, zeta_8447386_001)
stdev_8447930_000, stdev_8447930_001, var_8447930_000, var_8447930_001=rawstdev(water_8447930_center, zeta_8447930_000, zeta_8447930_001)
#stdev_8449130_000, stdev_8449130_001, var_8449130_000, var_8449130_001=rawstdev(water_8449130_center, zeta_8449130_000, zeta_8449130_001)
stdev_8452660_000, stdev_8452660_001, var_8452660_000, var_8452660_001=rawstdev(water_8452660_center, zeta_8452660_000, zeta_8452660_001)
stdev_8452944_000, stdev_8452944_001, var_8452944_000, var_8452944_001=rawstdev(water_8452944_center, zeta_8452944_000, zeta_8452944_001)
stdev_8454000_000, stdev_8454000_001, var_8454000_000, var_8454000_001=rawstdev(water_8454000_center, zeta_8454000_000, zeta_8454000_001)
stdev_8454049_000, stdev_8454049_001, var_8454049_000, var_8454049_001=rawstdev(water_8454049_center, zeta_8454049_000, zeta_8454049_001)
stdev_8461490_000, stdev_8461490_001, var_8461490_000, var_8461490_001=rawstdev(water_8461490_center, zeta_8461490_000, zeta_8461490_001)
stdev_8510560_000, stdev_8510560_001, var_8510560_000, var_8510560_001=rawstdev(water_8510560_center, zeta_8510560_000, zeta_8510560_001)
print("Raw deviation 000 is", stdev_8447930_000, stdev_8452660_000, stdev_8452944_000, stdev_8454000_000, stdev_8454049_000, stdev_8461490_000, stdev_8510560_000)
print("Raw deviation 001 is", stdev_8447930_001, stdev_8452660_001, stdev_8452944_001, stdev_8454000_001, stdev_8454049_001, stdev_8461490_001, stdev_8510560_001)
print("Raw variance 000 is", var_8447930_000, var_8452660_000, var_8452944_000, var_8454000_000, var_8454049_000, var_8461490_000, var_8510560_000)
print("Raw variance 001 is", var_8447930_001, var_8452660_001, var_8452944_001, var_8454000_001, var_8454049_001, var_8461490_001, var_8510560_001)
Raw deviation 000 is 0.15761010539349282 0.15839415469866305 0.17638921371327818 0.18480309631215222 0.16167192959745405 0.15176431002939975 0.15252784166588132
Raw deviation 001 is 0.15443665364010076 0.16163262182860716 0.17843309337918042 0.18567010900071587 0.16478444875469953 0.15829272214683426 0.15362372867059415
Raw variance 000 is 0.024840945322147912 0.025088708242704004 0.031113154714388518 0.03415218440655861 0.026137812819764135 0.02303240579869976 0.023264742483252165
Raw variance 001 is 0.02385067998755245 0.02612510443918954 0.03183836881286332 0.03447338937633772 0.027153914551390195 0.025056585884654876 0.02360025001065633
#Write a function for the corrected standard deviation
def correctedstdev(average_noaa, osom_000, osom_001):
#Model 001 does not include 12/31/17, so delete the last 24 hours of the NOAA data
average_noaa_001=[]
for i in range(len(average_noaa)):
average_noaa_001.append(average_noaa[i])
del average_noaa_001[-24:]
#Remove data that are nan values
new_buoy_000 = []
new_zeta_000=[]
for i in range(len(average_noaa)):
if str(average_noaa[i]) != 'nan':
new_buoy_000.append(average_noaa[i])
new_zeta_000.append(osom_000[i])
new_buoy_001 = []
new_zeta_001=[]
for i in range(len(average_noaa_001)):
if str(average_noaa_001[i]) != 'nan':
new_buoy_001.append(average_noaa_001[i])
new_zeta_001.append(osom_001[i])
#Find the average of the NOAA data and the OSOM data
average_noaa_000=np.nanmean(new_buoy_000)
average_osom_000=np.nanmean(new_zeta_000)
#NOAA data is taken with respect to MLLW and OSOM is not
#To correct this difference, we will take the difference between the averages and add it to the OSOM data
difference_000=average_noaa_000-average_osom_000
corrected_000=[]
for j in range(len(new_zeta_000)):
corrected_000.append(new_zeta_000[j]+difference_000)
average_noaa_001=np.nanmean(new_buoy_001)
average_osom_001=np.nanmean(new_zeta_001)
difference_001=average_noaa_001-average_osom_001
corrected_001=[]
for j in range(len(new_zeta_001)):
corrected_001.append(new_zeta_001[j]+difference_001)
slope_000, intercept_000 = np.polyfit(corrected_000,new_buoy_000,1)
slope_001, intercept_001 = np.polyfit(corrected_001,new_buoy_001,1)
fit_000=[]
for i in range(len(corrected_000)):
fit_000.append((slope_000*corrected_000[i])+intercept_000)
fit_001=[]
for i in range(len(corrected_001)):
fit_001.append((slope_001*corrected_001[i])+intercept_001)
differencelist_000=[]
for k in range(len(new_buoy_000)):
differencelist_000.append(new_buoy_000[k]-fit_000[k])
differencelist_001=[]
for k in range(len(new_buoy_001)):
differencelist_001.append(new_buoy_001[k]-fit_001[k])
stdev_000=np.std(differencelist_000)
stdev_001=np.std(differencelist_001)
var_000=np.var(differencelist_000)
var_001=np.var(differencelist_001)
return stdev_000, stdev_001, var_000, var_001
#fitdev_8447386_000, fitdev_8447386_001, fitvar_8447386_000, fitvar_8447386_001=correctedstdev(water_8447386_center, zeta_8447386_000, zeta_8447386_001)
fitdev_8447930_000, fitdev_8447930_001, fitvar_8447930_000, fitvar_8447930_001=correctedstdev(water_8447930_center, zeta_8447930_000, zeta_8447930_001)
#fitdev_8449130_000, fitdev_8449130_001, fitvar_8449130_000, fitvar_8449130_001=correctedstdev(water_8449130_center, zeta_8449130_000, zeta_8449130_001)
fitdev_8452660_000, fitdev_8452660_001, fitvar_8452660_000, fitvar_8452660_001=correctedstdev(water_8452660_center, zeta_8452660_000, zeta_8452660_001)
fitdev_8452944_000, fitdev_8452944_001, fitvar_8452944_000, fitvar_8452944_001=correctedstdev(water_8452944_center, zeta_8452944_000, zeta_8452944_001)
fitdev_8454000_000, fitdev_8454000_001, fitvar_8454000_000, fitvar_8454000_001=correctedstdev(water_8454000_center, zeta_8454000_000, zeta_8454000_001)
fitdev_8454049_000, fitdev_8454049_001, fitvar_8454049_000, fitvar_8454049_001=correctedstdev(water_8454049_center, zeta_8454049_000, zeta_8454049_001)
fitdev_8461490_000, fitdev_8461490_001, fitvar_8461490_000, fitvar_8461490_001=correctedstdev(water_8461490_center, zeta_8461490_000, zeta_8461490_001)
fitdev_8510560_000, fitdev_8510560_001, fitvar_8510560_000, fitvar_8510560_001=correctedstdev(water_8510560_center, zeta_8510560_000, zeta_8510560_001)
print("Fitted deviation 000 is", fitdev_8447930_000, fitdev_8452660_000, fitdev_8452944_000, fitdev_8454000_000, fitdev_8454049_000, fitdev_8461490_000, fitdev_8510560_000)
print("Fitted deviation 001 is", fitdev_8447930_001, fitdev_8452660_001, fitdev_8452944_001, fitdev_8454000_001, fitdev_8454049_001, fitdev_8461490_001, fitdev_8510560_001)
print("Fitted variance 000 is", fitvar_8447930_000, fitvar_8452660_000, fitvar_8452944_000, fitvar_8454000_000, fitvar_8454049_000, fitvar_8461490_000, fitvar_8510560_000)
print("Fitted variance 001 is", fitvar_8447930_001, fitvar_8452660_001, fitvar_8452944_001, fitvar_8454000_001, fitvar_8454049_001, fitvar_8461490_001, fitvar_8510560_001)
Fitted deviation 000 is 0.13795102988999638 0.15838648003170178 0.17638319404527314 0.1847790489370775 0.16167192844039482 0.14175939696883344 0.14248253424685225
Fitted deviation 001 is 0.14424900817815603 0.16163208859169828 0.17839514217521846 0.18554561357411126 0.1647840586746532 0.14484361367551746 0.1407885650243247
Fitted variance 000 is 0.019030486647710676 0.025086277056832668 0.03111103114161248 0.03414329692609088 0.026137812445636146 0.020095726628967303 0.02030127256540543
Fitted variance 001 is 0.020807776360381725 0.026124932062514605 0.031824826751716405 0.03442717471659342 0.027153785993291553 0.02097967242258255 0.019821420041608508
Once these statistical values are organized into a table, the values for version 000 look like this.
data000 = [(8447930, 'Woods Hole, MA', stdev_8447930_000, slope_000_8447930, int_000_8447930, fitdev_8447930_000),
(8452660, 'Newport, RI', stdev_8452660_000, slope_000_8452660, int_000_8452660, fitdev_8452660_000),
(8452944, 'Conimicut Light, RI', stdev_8452944_000, slope_000_8452944, int_000_8452944, fitdev_8452944_000),
(8454000, 'Providence, RI', stdev_8454000_000, slope_000_8454000, int_000_8454000, fitdev_8454000_000),
(8454049, 'Quonset Pt, RI', stdev_8454049_000, slope_000_8454049, int_000_8454049, fitdev_8454049_000),
(8461490, 'New London, CT', stdev_8461490_000, slope_000_8461490, int_000_8461490, fitdev_8461490_000),
(8510560, 'Montauk, NY', stdev_8510560_000, slope_000_8510560, int_000_8510560, fitdev_8510560_000)]
table000 = pd.DataFrame(data000, columns = ['Station ID', 'Station Location', 'Raw Standard Deviation', 'Scale (Slope)', 'Bias (Intercept)', 'Corrected Standard Deviation'])
table000.round(decimals=4)
| Station ID | Station Location | Raw Standard Deviation | Scale (Slope) | Bias (Intercept) | Corrected Standard Deviation | |
|---|---|---|---|---|---|---|
| 0 | 8447930 | Woods Hole, MA | 0.1576 | 0.9248 | 0.0312 | 0.1380 |
| 1 | 8452660 | Newport, RI | 0.1584 | 0.8598 | 0.0885 | 0.1584 |
| 2 | 8452944 | Conimicut Light, RI | 0.1764 | 0.8641 | 0.0987 | 0.1764 |
| 3 | 8454000 | Providence, RI | 0.1848 | 0.8641 | 0.1064 | 0.1848 |
| 4 | 8454049 | Quonset Pt, RI | 0.1617 | 0.8651 | 0.0877 | 0.1617 |
| 5 | 8461490 | New London, CT | 0.1518 | 0.9584 | 0.0241 | 0.1418 |
| 6 | 8510560 | Montauk, NY | 0.1525 | 0.9000 | 0.0499 | 0.1425 |
The values for 001 look like this. Overall, the corrected standard error is lower than the raw standard error which means we can empirically and linearly use bias and slope to improve the accuracy of OSOM tide predictions. Also, whether model 000 or 001 is more accurate varies from station to station, which should be looked into further to determine why.
data001 = [(8447930, 'Woods Hole, MA', stdev_8447930_001, slope_001_8447930, int_001_8447930, fitdev_8447930_001),
(8452660, 'Newport, RI', stdev_8452660_001, slope_001_8452660, int_001_8452660, fitdev_8452660_001),
(8452944, 'Conimicut Light, RI', stdev_8452944_001, slope_001_8452944, int_001_8452944, fitdev_8452944_001),
(8454000, 'Providence, RI', stdev_8454000_001, slope_001_8454000, int_001_8454000, fitdev_8454000_001),
(8454049, 'Quonset Pt, RI', stdev_8454049_001, slope_001_8454049, int_001_8454049, fitdev_8454049_001),
(8461490, 'New London, CT', stdev_8461490_001, slope_001_8461490, int_001_8461490, fitdev_8461490_001),
(8510560, 'Montauk, NY', stdev_8510560_001, slope_001_8510560, int_001_8510560, fitdev_8510560_001)]
table001 = pd.DataFrame(data001, columns = ['Station ID', 'Station Location', 'Raw Standard Deviation', 'Scale (Slope)', 'Bias (Intercept)', 'Corrected Standard Deviation'])
table001.round(decimals=4)
| Station ID | Station Location | Raw Standard Deviation | Scale (Slope) | Bias (Intercept) | Corrected Standard Deviation | |
|---|---|---|---|---|---|---|
| 0 | 8447930 | Woods Hole, MA | 0.1544 | 0.8164 | 0.0762 | 0.1442 |
| 1 | 8452660 | Newport, RI | 0.1616 | 0.8493 | 0.0952 | 0.1616 |
| 2 | 8452944 | Conimicut Light, RI | 0.1784 | 0.8651 | 0.0981 | 0.1784 |
| 3 | 8454000 | Providence, RI | 0.1857 | 0.8699 | 0.1019 | 0.1855 |
| 4 | 8454049 | Quonset Pt, RI | 0.1648 | 0.8589 | 0.0918 | 0.1648 |
| 5 | 8461490 | New London, CT | 0.1583 | 0.9757 | 0.0141 | 0.1448 |
| 6 | 8510560 | Montauk, NY | 0.1536 | 0.9289 | 0.0355 | 0.1408 |
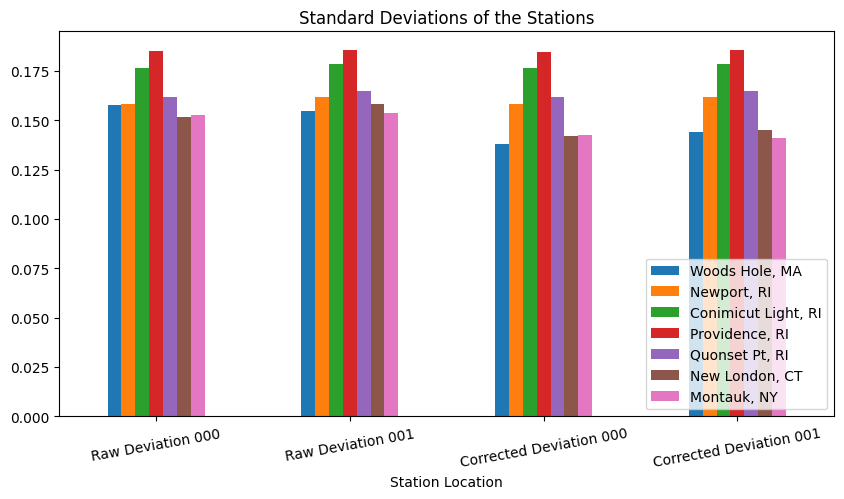
We can use a bar graph to visually represent the the values in the table above. This will allow us to more easily see which stations have the highest raw standard error, how much the corrected standard error lowers, and more.
#Create dataframe of standard error data
df = pd.DataFrame([['Raw Deviation 000', stdev_8447930_000, stdev_8452660_000, stdev_8452944_000, stdev_8454000_000, stdev_8454049_000, stdev_8461490_000, stdev_8510560_000],
['Raw Deviation 001', stdev_8447930_001, stdev_8452660_001, stdev_8452944_001, stdev_8454000_001, stdev_8454049_001, stdev_8461490_001, stdev_8510560_001],
['Corrected Deviation 000', fitdev_8447930_000, fitdev_8452660_000, fitdev_8452944_000, fitdev_8454000_000, fitdev_8454049_000, fitdev_8461490_000, fitdev_8510560_000],
['Corrected Deviation 001', fitdev_8447930_001, fitdev_8452660_001, fitdev_8452944_001, fitdev_8454000_001, fitdev_8454049_001, fitdev_8461490_001, fitdev_8510560_001]],
columns=['Station Location', 'Woods Hole, MA', 'Newport, RI', 'Conimicut Light, RI', 'Providence, RI', 'Quonset Pt, RI', 'New London, CT', 'Montauk, NY'])
# Plot grouped bar chart
df.plot(x='Station Location',
kind='bar',
stacked=False,
title='Standard Deviations of the Stations',
figsize=[10,5],
rot=10)
#Change legend location
plt.legend(loc='lower right')
<matplotlib.legend.Legend at 0x1776e2ca0>